# 前言
部分来源于网络,并注明来源(已丢失除外),性能优化、批处理则主要整理自 Unity 官方文档
注 1:参考文档均在对应位置标注,文章末尾也贴了对应链接
注 2:对文章内容,后续可能会还会进行调整
# 硬件
# GPU 的渲染架构
# IMR(Immediate Mode Rendering,主要用于 PC 平台)
- 即渲染模式。每个像素渲染的时候直接访问 DRAM,并写入到 FrameBuffer 上。PC 平台的显卡都是 IMR 架构
# TBR(Tile-Based Rendering,基于 Tile 渲染,主要用于移动平台)
为了减少 GPU 访问 SystemMemory 的次数(延迟高、功耗高),将屏幕分成一小块儿一小块儿,确保这一小块渲染所需要的绝大部分数据都能同时装进小小的 OnChip memory,从而实现整个渲染大部分操作都可以在带宽较高的 OnChip memory 上完成
- 大幅减少对显存带宽的消耗
TBR 是以牺牲执行效率为代价,换来功耗降低。在移动平台直接访问 FrameBuffer 会有很大的带宽开销,进而影响功耗。所以 TBR 把屏幕分成格子之后,每个格子可以访问 SRAM(OnChip memory),一整块都访问好之后,再整理转移回 DRAM
- 大部分手机的 GPU 用的都是手机的 System memory 和一块容量很小的,带宽比 System memory 更高的专供 OnChip memory
- SRAM,GPU 的 OnChip memory
- DRAM,显存,离 GPU 较远,容量大访问速度慢
- 从 GPU 直接对 FrameBuffer 的访问,就相当于一辆货车大量的在家(GPU)和市中心超市(DRAM)之间往返运输。带宽的消耗和发热量之大,是手机上无法接受的
- 对移动平台而言,功耗是第一位。因为功耗意味着发热量、耗电量、芯片大小等等。
- 对功耗影响最大的是带宽。所以对移动芯片而言,第一考虑的不是渲染性能,而是如何通过缓存减少带宽消耗。即,减少对显存的访问
- 实际上直接对 DRAM 进行读写速度是最快的。TBR 需要一块儿块儿的绘制然后往 DRAM 拷贝。可以简单理解为 TBR 是牺牲了执行效率,来解决更重要也更难处理的带宽功耗
# 其它
- DeferredRenderingPath:对 Tile-Based GPUs (移动平台) 启用了 NativeRenderPass 选项的有优化,没启用要避免。原理是 合并 GBuffer 和光照通道存储至 Title Memery 中以优化延迟渲染,NativeRenderPass 在 Tile-Based GPUs 应该启用
- URP 延迟渲染 + Native Renderpass 踩坑记录
利用移动端 TB (D) R 的硬件架构,相比于传统延迟管线在 basepass 结束后将 gbuffer store 回 system memory, 之后再在 lightpass 中 load 回来这种带宽压力极大的方案,Native Renderpass 可以在每个 tile 的 basepass 结束后将 gbuffer 保存在 On-Chip Memory 上,以供接下来的 lightpass 直接使用,直接优化掉了两个 pass 之间的 store/load 操作,极大减缓了带宽压力,这种形式的 rt 也被称之为 memoryless
# TBDR(Tile-Based Deferred Rendering 针对 TBR 做了进一步优化,主要是 PowerVR 在用)
基于 Tile 的延迟渲染。只对玩家能看到的像素做 pixel shader。通过 HSR 将不可见的点剔除掉。大幅减少对显存带宽的消耗
- IOS 一般都是 TBDR
- HSR (隐藏面消除) Hidden Surface Removal,TBDR 新增的一个阶段,在光栅化阶段真正开始前实现像素级裁剪。
TBDR,相对于 IMR,多了一个 FrameData 的数据,里面包含了有效信息,可以进行剔除操作
# MRT(Multi Render Targets)
OpenGL ES 多目标渲染,OpenGL ES 3.0 新特性,它允许应用程序一次渲染到多个缓冲区。
# Early-Z
在执行像素着色器之前,先进行一轮深度测试,避免会被深度测试剔除的片元,执行复杂的像素着色器的逻辑。这样可以减少显存带宽的消耗
- 如果没有 Early-Z,那么很有可能屏幕上一个像素点会被渲染七八次,显存带宽消耗成倍的增加
- discard 或 clip 会导致 Early-Z Culling 无效
# 渲染顺序
- 不透明物体,离摄像机近的先绘制,这样它会因为 ZTest 剔除掉后面的渲染内容,性能更好
- 半透明物体,必须从后往前画,先画离摄像机远的物体,才能保证渲染结果正确
- Shader 非常复杂的模型,尽量后绘制。更加容易被 Z-Culling 剔除掉
- 不透明物体 (2000)----AlphaTest 物体 (2450)---- 半透明物体 (3000),这个渲染顺序有利于 HSR 或者 Early-Z 的优化
- Alpha-Test 在不透明物体绘制完毕之后再绘制,可以避免 Alpha-Test 导致 EarlyZ 失效,最后绘制,至少不会影响到之前不透明物体的 EarlyZ
- RenderQueue2500,区分了不透明和半透明。半透明物体(2500 以上)永远在不透明物体(2500 以下)后绘制
- 如果物体的 RenderQueue 在 2500 的同一侧,则 sortingOrder 优先级更高:
- Camera Depth > Sorting Layer > Order In Layer > RenderQueue > 距离相机的距离
# 性能状态
# DrawCall
通常情况下,DrawCall 的准备工作比 DrawCall 本身更耗费资源
- 准备 DrawCall:CPU 设置资源并更改 GPU 上的内部设置,即渲染状态
- 对渲染状态的更改(例如切换到不同的材质)是图形 API 执行的资源密集型操作
- 由于渲染状态更改是资源密集型的,因此对其进行优化非常重要。优化渲染状态更改的主要方法是减少它们的数量
- 优化:
- 减少 DrawCall 调用数量,这同样会减少改变渲染状态的次数
- 合批:如果可以使用相同的渲染状态来执行多个 DrawCall,那么就可以将 DrawCall 组合在一起,而不需要执行太多的渲染状态更改
- Unity 提供优化:
- GPU instancing
- Static batching、Dynamic batching
- SRP Batcher
- 手动合批
注:对于移动设备,Drawcall 不只影响 CPU,还会影响到 GPU
- 在 PC 上 Drawcall 和顶点数量对 GPU 没有太多严重影响。但是对于 TBDR,DrawCall 过多意味着 FrameData 数据过多,严重情况下可能会出现内存放不下的情况,这种情况下对 FrameData 的访问速度奇慢
Unity - Manual: Optimizing draw calls
# SetPassCall
渲染 Pass 的数量:一帧中切换 Shader Pass 的次数,一个 Shader 可能包含多个用于渲染的 Pass,每个 Pass 都需要 Unity 绑定一个新的着色器,必然会带来 CPU 开销
- 内置渲染管线:是所有材质球的渲染 Pass 的数量
- URP:渲染不同 Pass 的数量,与内置管线以材质球为准不一样,以 Shader 和关键字都一样为准,其中渲染的 Pass 通道
- 注:经测试,两个同一个 Sahder 材质,内置渲染管线启用禁用时,Batches 和 SetPassCall 均发生变化,而 URP 仅 Batches 发生变化
Unity - Manual: The Rendering Statistics window
# 降低 CPU 渲染成本
- 通常,CPU 渲染时间的最大消耗是向 GPU 发送渲染命令的成本
- 渲染命令包括 DrawCall (绘制几何图形的命令)、以及在绘制几何图形之前更改 GPU 设置的命令
- 可考虑优化方式
- 减少渲染的对象数量
- 远景使用天空盒模拟
- 剔除
- 缩小相机的远裁剪平面
- Camera.layerCullDistances
- 减少渲染每个对象的次数
- 使用光照贴图
- 前向渲染中,减少实时光 (影响物体) 数量
- 注意实时阴影的使用,非常耗性能
- 合批
- 减少准备和发送渲染命令所需的工作量
- 减少渲染的对象数量
- 上面的优化方式,部分既可减轻 CPU 负担,也可以同时降低 GPU 消耗 (如减少渲染对象数量)
# 降低 GPU 渲染消耗
- 像素填充率问题
- 降低片段着色器的复杂度
- 减少 overdraw :UI、粒子和 Sprite
- 动态分辨率 (DynamicResolution)
- 内存带宽问题:一般由于纹理过多或分辨率过大
- 启用 3D 空间对象纹理的 Mipmap,会增加内存使用量和存储空间,但可以提高运行时 GPU 的性能
- 选择合适的压缩格式减小内存中纹理大小
- 顶点处理问题
- 降低顶点着色器的复杂度
- 优化网格
- LOD,会增加内存使用,但可以提高 GPU 效率
- 降低帧率,可以考虑比如打开静态 UI 后,降低帧率,即按需渲染
- OnDemandRendering:独立于所有其他子系统(如物理、输入或动画)来控制和查询有关应用程序渲染速度(注:独立于 Application.targetFrameRate)
Unity - Manual: Graphics performance fundamentals
- OnDemandRendering:独立于所有其他子系统(如物理、输入或动画)来控制和查询有关应用程序渲染速度(注:独立于 Application.targetFrameRate)
# 批处理
Unity 批处理顺序:
- SRP Batcher and static batching
- 注:Unity 还支持与 SRP Batch 兼容的 GameObjects 的静态批处理
- GPU instancing
- Dynamic batching
# 静态批处理 (Static batching)
- 两种方式,一种是编辑器标记 Static Batching,一种是运行时代码调用 StaticBatchingUtility 接口合并
- 编辑器标记的方式会在打包时统一合并,增加磁盘空间
- 代码合并则消耗运行时 CPU,且必须启用 Mesh 的 read/write
- 增加磁盘空间、内存消耗、运行时无法移动
- 将组合的 Mesh 转换到世界空间,并为它们构建一个共享顶点和索引缓冲区,使得一个 DrawCall 可以将合批对象都绘制出来
- 每个游戏对象都会创建一个 Mesh 副本,并将每个副本插入组合的 Mesh 中,意味着就算同一实例也会导致额外内存
- 好处如同名字一样,按照官方说法,可以显著降低 DrawCall 开销,对于可见的 Mesh 执行更轻量级的 DrawCall
- Unity - Manual: Static batching
- 注:需要先启用 PlayerSetting StaticBatching 选项
- 具有相同材质的对象才能进行批处理、对象不能为负缩放
# 动态批处理 (Dynamic batching)
运行时每帧在 CPU 上动态合并网格,只有当合并消耗小于 DrawCall 消耗时才是一种优化,在现代图形 API,例如 IOS (Apple Metal) 上,基本上是消耗大于收益
- 注:在现代消费类硬件上,动态批处理在 CPU 上所做的工作可能大于 DrawCall 本身的开销。这会对性能产生负面影响(言外之意就是不要用了,HDRP 已经移除支持)
- 注:需要先启用 PlayerSetting DynamicBatching 选项
限制
- 具有相同材质的对象才能进行批处理 (除 shadow caster rendering 外)
- 对象不能为负缩放
- 使用顶点属性低于 900 个,例如 Shader 同时使用 顶点位置、顶点法线、UV0、UV1 和顶点切线,则 Unity 只能批处理 180 个顶点 (900/5=180)
- 如果有光照贴图,必须指向同一个地方 (可忽略)
- 多 Pass 支持也有问题,例如只有第一个 Pass 生效,后续额外的像素光是无效的
# 手动合批
- 使用 API Mesh.CombineMeshes
- 注:手动合批的网格无法单独剔除
# GPU instancing
- 两种方式,一种是直接由 Unity 引擎自动处理,一种是使用代码一次性绘制
- 支持 MaterialPropertyBlock 修改 Shader 中定义的 Instancing 属性
- 材质自带的与 SRPBatcher 不兼容,优先 SRPBatcher
- 如果开启了 SRP Batcher ,需要移除 Shader 中对 SRP Batcher 的兼容性
- 只要 UnityPerMaterial 常量缓冲区中不存在材质属性,就会使着色器与 SRP Batcher 不兼容
- 使用 MaterialPropertyBlock 也会使 SRP Batcher 不兼容
- 如果开启了 SRP Batcher ,需要移除 Shader 中对 SRP Batcher 的兼容性
- 注:使用完全相同的材质渲染大量相同的网格,GPU 实例化可能比 SRP Batcher 更高效
# API
- Graphics.RenderMeshInstanced:可以使用实例化着色器多次渲染同一网格
- 注 1:RenderParams.worldBounds 可以自定义边界
- 注 2:该接口一次最多只能渲染 1023 个实例
- Unity - Scripting API: Graphics.RenderMeshInstanced
- Graphics.RenderMeshIndirect:使用 commandBuffer 命令进行实例化渲染 (对实例数量没有限制)
- 注 1:RenderParams.worldBounds 可以自定义边界
- 注 2:要求支持 compute shaders,着色器中有额外取值方式需求
- Unity - Scripting API: Graphics.RenderMeshIndirect
- 注:其它还有 DrawMeshInstanced、DrawMeshInstancedIndirect (可以直接做剔除) 等 API 效果同上,不过据说 RenderMeshInstanced 接口更新,例如接受 NativeArray
- 注:可通过 SystemInfo.supportsInstancing 判断平台是否支持
- 缺点:Unity 会自动计算此网格的所有实例的边界,并会将该网格的所有实例作为单个实体进行剔除和排序 (所以优先级才在 SRPBatcher 之下吧)
# 兼容性
- OpenGL ES 3.0+(3.1 均没问题)
- IOS 的 Metal 均支持 (Metal 从 iPhone 5s 开始支持)
- 具有相同材质、同一个 Mesh 的对象才能进行批处理
# SRP Batcher
- 支持 mesh 或 skinned mesh(非粒子)
- 不支持 MaterialPropertyBlock,使用 MaterialPropertyBlock 会导致 SRP Batcher 兼容失败
- 允许不同材质,同一个 Shader,同样的变体即可
- 支持代码启用禁用:GraphicsSettings.useScriptableRenderPipelineBatching = true
# 工作原理
一般优化 DrawCall 的方式是减少调用数量,而 SRP Batcher 则主要减少了绘制调用之间的渲染状态更改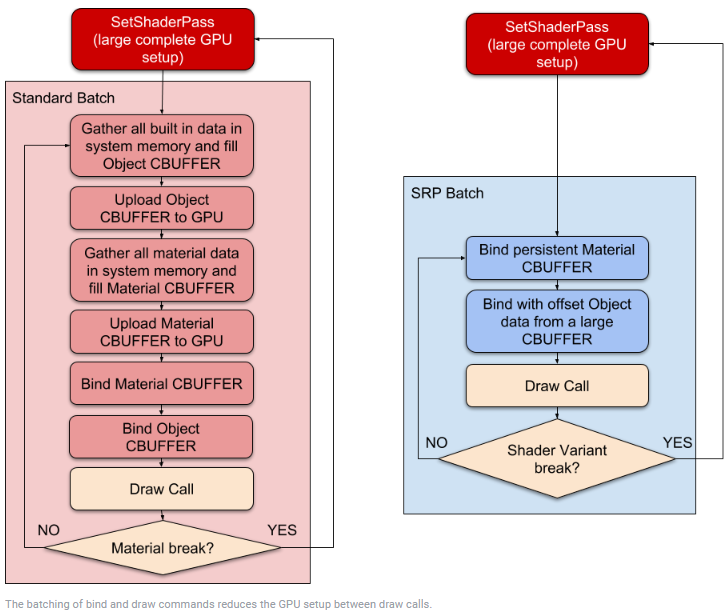
SRP Batcher 通过一系列组合将 bind 和 draw 命令合并,每个命令序列称为 SRP Batch
为优化性能,一个 SRP Batch 应包含尽可能多的 bind and draw 命令 (少用 Shader 变体)
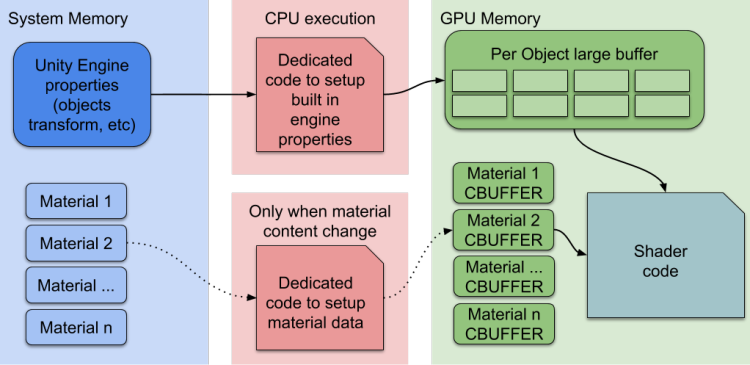
当检测到新的材质时,CPU 会绑定相关属性到 GPU 常量缓冲区 (constant buffers),使材质属性持久保存在显存中,若材质没有发生更改,SRP Batcher 就不会更改渲染状态
- 所有材质均持久存在于 GPU 的显存 (常量缓冲区) 中
- 随后 CPU 再使用专门方式在 GPU 大型常量缓冲区进行每个物体的属性更新或管理
![]()
- 当 Shader 发生变化时,只需要
- 重新绑定 Material CBUFFER (材质属性)
- 重新绑定 large CBUFFER (物体属性)
- 然后就可以执行新的渲染 (DrawCall)
Unity - Manual: Scriptable Render Pipeline Batcher
# BatchRendererGroup(BRG)
物体不会参与到 Unity 场景 Render 的剔除,他真正的是管理每一个物体的剔除,也就是说如果有 1000 个小物体他们会分别计算剔除。最重要的是,RenderBatchGroup 给你的是一组相机参数,这意味着我们能在这里能对于每个 View 分别做 LOD 相关的东西
- 比 GPU Instancing 更高效,并且可以在 CPU 上使用多线程、可以自定义剔除等
- 建立在 SRP Batcher 之上
- 要求
- 需要禁用变体剔除选项,避免 Shader 中 DOTS Instancing 变体被剔除
- 需要启用不安全代码 (Allow unsafe code)
- 兼容性:OpenGL, GLES and WebGL 暂不支持
- https://forum.unity.com/threads/new-batchrenderergroup-api-for-2022-1.1230669/
# 使用步骤
- 创建 BatchRendererGroup 实例
- new BatchRendererGroup(this.OnPerformCulling, IntPtr.Zero);
- 注册 Mesh 和材质
- 可以重复注册,内部使用引用计数维护注册数量,注册一次递增 1,注销一次减 1,引用计数达到 0 内部才会才真的注销
- 已注册 Mesh 或 Material 的 RegisterMesh 或 RegisterMaterial 调用返回与上一次调用相同的 BatchMeshID 或 BatchMaterialID(若彻底注销后,重复注册返回不同 id)
Unity - Manual: Creating a renderer with BatchRendererGroup
# DOTS Instancing
DOTS 实例化比传统实例化更具有优势
- 实例数据存储在 GraphicsBuffer 中,并在 GPU 上保持持久性
- 这意味着 Unity 不需要在每次渲染实例时再次设置它,仅在实例实际更改时设置数据
- 注:传统的实例化需要一个引擎在每帧为每个实例设置所有数据
- 设置实例数据的过程与设置 DrawCall 调用是分开的
- DrawCall 消耗更低
- BRG 通过 SRP Batcher 一个特殊的快速通道使得每个 DrawCall 只做最少工作
- 可以更好地控制在每次绘制调用中渲染什么
- 绘制调用的大小不再受常量或统一缓冲区中可以容纳多少实例数据的限制
- BRG 可以通过一个 DrawCall 来渲染更多的实例数量
- 注:实例索引的数量仍然限制了绘制调用的大小,因为每个索引仍然需要一些数据。然而,一个索引消耗的内存远远少于一组完整的实例化属性,这意味着更多的实例可以放在一个常量或统一的缓冲区中。例如,每个索引需要 16 个 byte,因此如果特定平台上缓冲区的内存限制为 64kb,则缓冲区中可以容纳 4096 个索引
- 如果每个实例对给定的属性使用相同的值,则可以让所有实例从内存中的同一位置加载该值。这样可以节省内存和复制每个实例的值所花费的 GPU 周期数
要求
- #pragma target 4.5 或更高
- 着色器编译目标级别 - Unity 手册
- #pragma multi_compile _DOTS_INSTANCING_ON
- 声明 DOTS Instanced 属性块
- Unity - Manual: DOTS Instancing shaders
# 光照
# 阴影
阴影贴图本质上是从光源视角投射的纹理
注 1:URP 中,额外光源若选顶点光照则不能设置阴影
注 2:内置渲染管线未找到直接设置顶点光
# Cascaded Shadow Maps(CSM)
使用多张阴影贴图实现阴影的一种技术
- 阴影贴图的缺点:空间中对象在阴影图比例太小,采样精度不够,产生锯齿 (增加阴影图分辨率可以改善,但治标不治本,同时也会增加内存消耗)
- 而且一张阴影图会导致近处物体采样精度不够,远处物体采样精度浪费
- 问题是阴影贴图分辨率低,级联阴影的关键就是生成和使用不同精细度的阴影贴图
基础的阴影贴图方法对于大型场景渲染显得力不从心,由于阴影贴图分辨率问题,很容易出现阴影抖动和锯齿边缘现象
Cascaded Shadow Maps (CSM) 方法根据对象到观察者的距离提供不同分辨率的深度纹理来解决上述问题
- 在一张阴影贴图中捕捉所有对象需要阴影贴图具有非常高的分辨率
- 使用多张阴影贴图就可以解决这个问题,对于近处的场景使用较高分辨率的阴影贴图,对于远处的场景使用粗糙的阴影贴图,在两张阴影贴图过渡的地方选择其中一张使用
注:实时阴影,仅适用于平行光 (大场景最好至少 2 个,默认是 1 个 - 即仅一张)
注:因为需要多张阴影,因此会增加 DrawCall
Cascaded Shadow Maps (CSM) 实时阴影的原理与实现
Unity 实时阴影实现 ——Cascaded Shadow Mapping_unity 阴影
# Bias
阴影偏移,解决自遮挡阴影瑕疵 (Shadow acne) 而提出
因为 DepthMap 分辨率的关系,每个 Depth 像素对应地面上的一小块区域,而不是一个点
- 这块区域中,如果都按照这个 Depth 值进行计算的话,就有的地方比 Depth 值大,有的地方比 Depth 值小,所以就会重现交错
- (因此除 Bias 外也可以通过提升 DepthMap 的分辨率解决,但是...)
- 当光源离得特别远的时候,你从光源角度看,整个场景可能都挤在几个像素里,特别的小,所以没办法只通过调整深度图的分辨率来控制 (MipMap?Cascade?)
因此在和 ShadowMap 中离散化的深度比较时,将这个深度加大一点点,这样只有当 ShadowMap 中的深度显著大于计算出来的深度时,才判断为产生阴影
注:若 Bias 值太大也会有副作用,例如会导致对象的底部与阴影有一定的距离,造成 "浮空" 的错觉
关于 Shadow Mapping 产生的 Shadow Acne,我的理解是不是有问题? - 知乎
# 渲染方式
浅谈延迟渲染、移动 GPU 架构和 Metal
- 前向渲染是一种非常直接的渲染方式,我们提交的 mesh,经过 vs、gs、fs 等 shader,直接绘制到 color buffer 等待输出到屏幕,很线性的 Per-Object/Per-Light 方式进行绘制。—— 光照对性能影响很大
- 前向渲染渲染 n 个物体在 m 个光源下的着色,复杂度为 O (n*m) 次。
- 延迟渲染 (Deferred Rendering),即延迟着色(Deferred Shading),顾名思义,是将着色计算延后进行处理的一种渲染方法,可以将延迟渲染 ( Deferred Rendering) 理解为先将所有物体都先绘制到屏幕空间的缓冲(即 G-buffer,Geometric Buffer,几何缓冲区)中,再逐光源对该缓冲进行着色的过程,从而避免了因计算被深度测试丢弃的片元着色而产⽣的不必要的开销
- 对应于前向渲染 O (m*n) 的复杂度,经典的延迟渲染复杂度为 O (n+m)
- 延迟管线下多了深度、法线、颜色等几张 G-Buffer。这些都是屏幕大小的尺寸的 Render Target,所带来的内存以及带宽压力很大
- 延迟渲染有以下特点:
- 内存开销较大
- 读写 G-buffer 的内存带宽用量是性能瓶颈。
- 对透明物体的渲染存在问题。在这点上需要结合前向渲染进行渲染。
- 对多重采样抗锯齿(MultiSampling Anti-Aliasing, MSAA)的支持不友好,主要因为需开启 MRT。
- 由于 Deferred Shading 的 Deferred 阶段是在完全基于 G-Buffer 的屏幕空间进行,这也导致了物体材质信息的缺失,这样在处理多变的渲染风格时就需要额外的操作。
- 针对上文的问题,业界有主流有两种优化方式:
- Light Pre-Pass 即 Deferred Lighting 延迟光照技术,通过减少经典延迟渲染所使用的 G-Buffer 数量来提高性能
- 分块延迟渲染,tile-based Deferred Rendering。该方法通过可以在一次绘制处理多个光源,以及来降低对 G-Buffer 的读写开销
- 影响功耗的最大因素是什么?带宽。
# 前向渲染 (ForwardPass)
# 渲染方式
浅谈延迟渲染、移动 GPU 架构和 Metal
- 先渲染 ShadowMap
- 然后从近至远渲染不透明物体
- 最后从远至近渲染透明物体
- 因为有深度测试,因此先渲染近处物体可以提前剔除不可见像素,透明物体则相反,需要混合叠加,因此由远及近
- unity 规定,2500 以下对象由近及远,以上由远及近
- earlyz:几何阶段与片元着色器阶段之间(光栅化之后,片元着色器之前),不过最终还是会走一次正常的后置深度测试
- 若检测到在片元着色器存在抛弃片元和改写深度的操作,则 earlyz 优化将被弃用
- 例如使用了 alphatest 渲染物体(因为片元是在片元着色器丢弃的,丢弃后,它之后的片元就得显示,若进行了 earlyz 就会出问题)
# 前向实时剔除
- 前向渲染是逐对象渲染,若一个物体挡住了另一个物体,执行的渲染就无效了,为了解决这些问题,也提出了一些解决方法:如 Early-z 、Z-Prepass 、 Hi-Z
- Early-z:在光栅化阶段,每个模型的深度就已经写入深度缓存了,先进行深度剔除再计算光照
- Z-Prepass:首先把整个场景中的模型都渲染一遍,全部都写入 Z-Buffer ,这次渲染除了 Z-Buffer 其他的信息都不计算。然后再渲染一遍场景,这次渲染关闭深度写入,每个像素和 Z-Buffer 中已经存在的深度信息进行对比,只有通过测试的像素才会计算光照。这种方法虽然避免了无效的光照计算,但是却执行了两次顶点着色器,所以最好是在场景中物体的光照计算非常复杂但是顶点数量却不是很多的情况下使用。
- Hi-Z :上面两种方法都是在 GPU 段进行的,而 Hi-Z 这种方法是在 CPU 端进行的,在几何体被提交到 GPU 之前会进行遮挡测试,如果几何体被别的物体遮挡了就不会提交到 GPU
# 光照
- 多一个光源就会多一个 DrawCall,是因为重要光源的原因,在 ForwardPass 渲染路径中,默认最多支持 4 个 逐像素的重要光源 (可设置),光源默认 Auto ,将光源设置为 Net Important 即可减少该消耗。(不重要的顶点光源同样是限制 4 个,Shader 中 unity_LightColor [4]--> 仅 BasePass)
- BasePass(LightMode=ForwardBase):最重要逐像素平行光源 (_LightColor0)+ 不重要光源 (unity_LightColor [4])+LightMap + 环境光
- AdditionalPass(LightMode=ForwardAdd):其它逐像素重要光源 (_LightColor0) 在额外 Pass 渲染,与前者叠加,多一个就会导致多一份 DrawCall
# 阴影 (Forward)
游戏中的动态阴影
- 分为两部分,自己接收阴影以及投射阴影,MeshRender 上也可以单独设置
- 是否有阴影跟三个条件有关:(1) Shader 中的 接收投射阴影 Pass;(2) Render 上的接收投射开关;(3) 光源是否设置阴影
- Shader 中阴影投射 Pass 必须:
- 打 Tags {"LightMode":"ShadowCaster"},标记该 Pass 专用于阴影投射
- 增加预编译指令 #pragma multi_compile_shadowcaster
- 在顶点、片段中调用 Unity 提供的预定义进行处理:V2F_SHADOW_CASTER、TRANSFER_SHADOW_CASTER_NORMALOFFSET、SHADOW_CASTER_FRAGMENT
- V2F_SHADOW_CASTER:顶点到片段数据变量
- TRANSFER_SHADOW_CASTER_NORMALOFFSET:在顶点 Shader 函数中计算了 物体顶点世界坐标 - 光源坐标,即当前顶点到光源向量,然后再转 clip 裁剪空间
- SHADOW_CASTER_FRAGMENT:在片段 Shader 函数中将顶点到光源向量转长度,计算深度(光源设置的 shadowbias 就在这里用的:长度 + unity_Light_ShadowBias.x)
- Shader 中阴影接收 Pass 必须:
- 打 Tags {"LightMode":"ForwardBase"},标记该 Pass 为向前渲染
- 增加预编译指令 #pragma multi_compile_fwdbase
- 在顶点、片段中调用 Unity 提供的预定义进行处理:SHADOWCOORDS (1)、
- SHADOWCOORDS (ID):ID 是个数值,表示使用的 TEXCOORD+ID,保存顶点函数通过 ComputeScreenPos (o.pos) 计算的 showCoord
- TRANFER_SHADOW (o):通过顶点 clip 裁剪空间坐标计算屏幕空间阴影采样坐标 ComputeScrrenPos (o.pos)
- SHADOW_ATTENUATION (i):根据 showCoord 采样阴影颜色,返回叠加的阴影强度值。
- Forward:
- 在光源位置渲染一张深度图,然后找物体 Shader 中的特殊的 阴影投射 Pass
- 在正常渲染时,判断当前深度是否大于阴影深度,叠加阴影颜色
- 仅在使用像素光照的情况下才渲染法线贴图、光照剪影和实时阴影。此外,在像素模式下渲染时,聚光灯形状和点光源高光看起来要好得多。
- CSM (Cascaded Shadows Map):级联阴影,将摄像机前面空间分成多个层级,分别 (以不同分辨率) 绘制各个层级物体阴影深度,合成一张连续的 CSM 贴图
- https://docs.unity.cn/cn/2018.4/Manual/LightPerformance.html
# 延迟渲染 (Deferred)
- 延迟渲染就是把光照计算延迟到深度测试之后的渲染方式,只渲染可见的像素,不会有无效的计算。
- 延迟渲染的思路就是先把几何体的信息都渲染到二维空间中(G-Buffer),然后把 G-Buffer 整体进行光照计算,G-Buffer 中存在的信息都是会最终呈现在屏幕上的,不会有无效计算。
- Z-prepass 也是先渲染出深度缓存进行深度测试后再计算光照的,和延迟渲染有什么不同?最大的不同点就在于 G-buffer ,Z-prepass 在深度测试后也还是按照一个几何体渲染完再进行下一个这种方式来渲染的 ,延迟渲染是几何体的信息传递到 G -buffer 之后就和几何体没多大关系了,接下来的操作都是对 G-buffer 进行的。
- G-Buffer:不同的引擎处理可能不一样,例如 PBR 会有深度、颜色、法线、世界空间坐标、模板、金属、粗糙、高光这些信息
- 缺点:
- 前向渲染只需要深度缓冲和最终的颜色缓冲就够了,延迟渲染需要缓存的信息实在太多了,这造成了带宽的开销大幅增加。
- 对于半透明无能为力,所有半透明的物体都需要等待不透明物体以延迟渲染完成之后,在用前向渲染的方式渲染半透明物体。
- 无法记录通过半透明对象可见的对象和当前对象本身的深度和法线
- 分块延迟渲染:
- 虽然延迟渲染已经把光照数量和三角形数量不再关联了,但是当场景中的光源数量不断上升之后,就算是延迟渲染也有点撑不住。
- 这时就需要分块延迟渲染,它的思路是把 G-Buffer 分成很多个小块,分析每个小块受到哪些光源的影响,然后逐个分块进行着色,那些受光源影响的数量少的小块就不需要那么多的光照计算了。这种渲染方式在光源数量少的情况下效果不明显,但是光源数量越多它优化的性能也就越多。
# 前向与延迟渲染路径比较
- 后处理方式不同。需要深度信息进行后处理时:前向渲染需要单独渲染一张深度图;延迟渲染直接从 G-buffer 中的深度图进行计算。
- 着色计算不同(shader)。延迟渲染光照计算统一在 Lighting Pass 里计算,只能用一个光照模型,需要其它光照模型只能切换 Pass。
- 抗锯齿方式不同
# Forward+ 渲染
思路是将屏幕划分为一个一个的块儿,控制每个块儿的影响灯光数量,从而减轻运算压力,让前向渲染也可以处理多光源的情况。
# 后期处理
# 抗锯齿
- MSAA (Multi Sample AA):基于多边形抗锯齿,增加像素采样数 (增加额外显存及带宽开销),只能用于 Forward,有 2X、4X
- 对空间进行 4 倍采样,进行着色时,考虑 4 个子像素对同一个几何体的覆盖率;若三角形对这 4 个采样点的覆盖率是 100%,则仅进行一次着色,否则都需要着色,并根据每个三角形占据的采样比例计算该点平均值
- 现代的几何体密度较高,性能消耗也会比较高
- FXAA (Fast Approximately AA):后处理抗锯齿,图形边缘进行柔化,速度很快但会糊。
- SMAA (Subpixel Morphological):后处理形态抗锯齿,改进了对模型边缘的判定算法,效果比 FXAA 更好,但是消耗比 FXAA 高一倍
- TAA (Temporal AA):时域抗锯齿,子像素采样点分布到多帧,需要运动矢量 (motion vectors),原理是,通过 Motion Vector,找到上一帧的当前像素点的信息,然后混合,抖动投影矩阵的做法被称为 Jitter
- 涉及两个 pass:渲染动态物体的运动矢量至速度缓存与 TAA
- 抗锯齿 (Anti-aliasing) - Unity 手册
- Unity Quality 内置的就是 MSAA, 在 URP 中,渲染管线可以设置 MSAA,相机后处理可以选择 FXAA、SMAA,两者可以叠加。URP 不自带 TAA (缺少正确的 Motion Vectors),【TAA 与 MSAA 不能叠加 -- 待定】
- 官方推荐:FXAA -- 移动端,SMAA、TAA-- 桌面和主机
- Post Processing v2 倒是支持 TAA,但是 URP 集成的 PP 没有支持 (缺少 Motion Vectors 数据),且内置的 Post Processing 替代了 PPv2 (post-processing-and-urp-the-plan)
- 速度快慢:FXAA->SMAA->MSAA->TAA
- U3D 各种抗锯齿哪个好?各自特点是什么?性能如何?什么平台用什么合适?
# 屏幕效果
- Bloom 效果
- 提取亮度、模糊处理、以及合并光晕
- 提取原图像,给定一个阈值,使用高斯模糊阈值范围上的图像。再与原图相加,获得 bloom 效果
- 景深
- 近距离模糊
- 焦点范围清晰
- 远距离模糊
- 注:可能需要用到深度,另外听说还有种物理景深算法
# 性能优化
- 减少提交次数 DrawCall,减少数据交换量,带宽优化、也是显存优化、
- 减少 CPU 与 GPU 的数据同步。减少 CPU 与 GPU 的数据同步也是一个方向,怪物尽可能由 GPU 绘制,最大可能减少数据同步,以达到最高异步效率
- 可变分辨率
- Shader:避免不同数据类型混用或者叫避免不必要的精度转换,例如 half 和 float,精度转换也是有消耗的
- 现在新型 GPU fixed 可能已经没了,等价于 Half
- 3D 贴图开启 Mipmap,以空间换时间
- 使用 Bilinear 代替 Trilinear 过滤
- 减少 Anisotropic 过滤采样数量
- 使用 LightMap,如果实在要使用实时阴影,可以考虑 Subtractive + 低分辨率阴影配合正确的阴影级联 (cascade) 设置 (级联仅适用于方向光)
- BVH
# 渲染调试
FrameDebugger
# 其它
# 模型
- 网格主要由:顶点、三角形索引数组、UV 三个基础数据组成
# 动画
- 分为两种:一种是用一种算法改变顶点位置,为顶点动画;另一种是用骨骼影响网格顶点,为骨骼动画。两种方式都是通过在每一帧偏移模型网格上的顶点,让模型变形从而实现动画,最终原理其实一样。
- 传统骨骼动画:每个顶点都有骨骼权重数据(被哪些骨骼影响,权重多少),在 unity 中可以设置每个顶点最多受四个骨骼权重影响 —— 传统骨骼动画由骨骼点与顶点权重数据计算得到,顶点与骨骼数量越多,有效权重数据越多,cpu 消耗也越大
- skinmesh:bindposes 为旋转矩阵,是为了实现父节点旋转位移时更快计算出子节点的位移旋转的变化矩阵(父子节点有相对位置关系,相对位置,相对角度,相对比例不变)
- 传统骨骼动画计算:CPU 计算骨架 ->GPU 顶点蒙皮
- 贴图骨骼动画:动画信息存储为图片,VertexShader 通过 tex2dlod 采样 (贴图模式采用 Point)
- 通过 CPU 计算全单位 Mask 图:播放哪个动画,第几帧。一张贴图包含所欲单位实时状态信息,只有一次数据同步。
- 大批量实例化绘制 (GPU Instancing):DrawMeshInstanced,该函数一般用于加速静态物体,批量一次性绘制一个 Mesh 多次。由于动态物体有动画,难以完全一致 (当对象足够多的时候,当前帧动画可能一致就能用了),形成动画对象大批量实例化技术。
- 批量化 GPU 阴影
# URP
- URP 多相机使用:https://zhuanlan.zhihu.com/p/351638959
- Depth Priming (Pre-Z Pass):OverDraw 过度绘制可以启用,但是要避免在 Tile-Based GPUs (移动平台),提高半透明物体效率?
- 优化 OverDraw,会增加 DrawCall,需要判断是否是正优化。
- 只能用于 Forward,自定义 Shader 需要手动添加 DepthOnly Pass
- 手机上与 MSAA 同时开启会比 DrawCall 开销还要大
- DrawCall 或其它图形 API 调用
- RenderingDebuger:URP 调试工具
- URP 配置 — 保姆级新手指南
光照
- 注:额外光源若选顶点光照则不能设置阴影
# 参考文档
- 图形学基础篇
- (十)、图形渲染进阶知识
- FrameDebugger
- URP 延迟渲染 + Native Renderpass 踩坑记录
- Unity - Manual: Optimizing draw calls
- Unity - Manual: The Rendering Statistics window
- Unity - Manual: Graphics performance fundamentals
- Unity - Manual: Static batching
- Unity - Scripting API: Graphics.RenderMeshInstanced
- Unity - Scripting API: Graphics.RenderMeshIndirect
- Unity - Manual: Scriptable Render Pipeline Batcher
- https://forum.unity.com/threads/new-batchrenderergroup-api-for-2022-1.1230669/
- Unity - Manual: Creating a renderer with BatchRendererGroup
- 着色器编译目标级别 - Unity 手册
- Unity - Manual: DOTS Instancing shaders
- Cascaded Shadow Maps (CSM) 实时阴影的原理与实现
- Unity 实时阴影实现 ——Cascaded Shadow Mapping_unity 阴影
- 关于 Shadow Mapping 产生的 Shadow Acne,我的理解是不是有问题? - 知乎
- 浅谈延迟渲染、移动 GPU 架构和 Metal
- 浅谈延迟渲染、移动 GPU 架构和 Metal
- 游戏中的动态阴影
- https://docs.unity.cn/cn/2018.4/Manual/LightPerformance.html
- 抗锯齿 (Anti-aliasing) - Unity 手册
- post-processing-and-urp-the-plan
- U3D 各种抗锯齿哪个好?各自特点是什么?性能如何?什么平台用什么合适?
- FrameDebugger
- https://zhuanlan.zhihu.com/p/351638959
- URP 配置 — 保姆级新手指南
