# 前言
之前听到运营那边报我们游戏可能会出现崩溃问题,主要是韩服,三星机器。
于是拿了日志来看,主要信息如下:
2022-07-07 14:58:35.666 10105-11685/? E/Unity: Using memoryadresses from more that 16GB of memory
(Filename: Line: 120)
2022-07-07 14:58:36.069 10105-11685/? E/CRASH: signal 11 (SIGSEGV), code 1 (SEGV_MAPERR), fault addr 00000000005ce87f
2022-07-07 14:58:36.069 10105-11685/? E/CRASH: *** *** *** *** *** *** *** *** *** *** *** *** *** *** *** ***
2022-07-07 14:58:36.069 10105-11685/? E/CRASH: Build fingerprint: 'samsung/d1xks/d1x:12/SP1A.210812.016/N971NKSU2HVE9:user/release-keys'
2022-07-07 14:58:36.069 10105-11685/? E/CRASH: Revision: '23'
2022-07-07 14:58:36.069 10105-11685/? E/CRASH: pid: 10105, tid: 11685, name: Thread-21 >>> com.gamemorefun.sgztw <<<
2022-07-07 14:58:36.069 10105-11685/? E/CRASH: x0 0000000000000000 x1 000000715477cf1c x2 0000006ec75ced60 x3 0000006d857acc28
2022-07-07 14:58:36.069 10105-11685/? E/CRASH: x4 000000000000007c x5 0000000000000000 x6 000000716ad1c000 x7 000000001fdcdd1e
2022-07-07 14:58:36.069 10105-11685/? E/CRASH: x8 0000000000000000 x9 00000000ffffffff x10 0000000000000090 x11 0000000000000008
2022-07-07 14:58:36.069 10105-11685/? E/CRASH: x12 0000fffffffff3ff x13 0000000000000020 x14 0000000000800000 x15 0000000000000001
2022-07-07 14:58:36.069 10105-11685/? E/CRASH: x16 0000006dad6574b0 x17 00000071546e0b70 x18 0000006d857ad0c4 x19 0000006dad6ff8b0
2022-07-07 14:58:36.069 10105-11685/? E/CRASH: x20 0000006cba745fe0 x21 0000006dad6ff8b0 x22 0000006dad6ff8e0 x23 000000000000005d
2022-07-07 14:58:36.069 10105-11685/? E/CRASH: x24 0000006dad6fd050 x25 00000000005ce597 x26 0000000000000018 x27 3fd1d9b7b46c74bd
2022-07-07 14:58:36.069 10105-11685/? E/CRASH: x28 00000000000027d4 x29 0000006d857ad000 x30 0000006dac83d4e4
2022-07-07 14:58:36.069 10105-11685/? E/CRASH: sp 0000006d857acfb0 pc 0000006dac83d53c pstate 0000000060000000
2022-07-07 14:58:36.069 10105-11685/? E/CRASH: backtrace:
其中关键字就是 『Using memoryadresses from more that 16GB of memory』,通过查询,可以找到一些,例如官方论坛:https://developer.unity.cn/projects/622b33a7edbc2a001b6f7776
这里解释得知,是由于安卓新版系统内存分配器更换导致 Unity 出现的 BUG,并且 Unity 也在后续版本更新中同步解决了这个问题,然而修复版本并不包括 2017:
- 2018.4.30
- 2019.4.15
- 2020.1.14
- 2020.2.0b12
- 2021.1.0a4
恰好我们项目使用的是 Unity2017,因此这种情况除更新 Unity 之外恐怕也别无他法。
于是就想升级,个人就吭吭哧哧在自己电脑上进行版本升级的兼容性测试了,开始用 2018 打开瞧了瞧,并出了个 PC 包,感觉没啥大问题,后来索性又用 2019 打开了来看,点了点发现了这么个 UGUI 的图文混排以及超链接失效问题。
(注:开始还以为只 2019 被改了,事实证明,新版本 Unity2018 其实也有这问题,据说 Unity2018 从 2018.4 也改过了,Unity2019 大概是从 2019.2 修改)
我们项目的图文混排以及超链接,都是通过一个叫 AorTextIncSprites 脚本实现,该脚本继承于 MaskableGraphic ,并复制了 Unity5.6 的 UGUI 源码,在其基础上加入了超链接和表情的图文混排支持 —— 相当古老的代码了,不过还能工作。
只是拿到 Unity2019 之后,这两个额外的功能都出现了些问题,例如超链接有的无法正确生成点击区域导致无法触发对应事件、图文混排直接糊掉 —— 表现为绘制整个图集,大概就这么个样子:
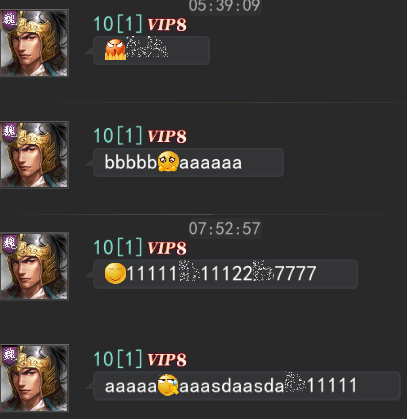
# UGUI 顶点数据
UGUI 顶点数据中,据说从 2019.2、2018.4 开始,全都不再包含富文本数据,导致以往涉及到 UGUI 顶点修改的相关代码,能够正常工作的都不再正常。
主要受影响的有:图文混排、超链接、竖行排行 (VerticalText)
# 超链接
超链接的问题,主要体现在聊天频道中,某些含有坐标的信息,无法点击坐标 —— 经过检查,内部问题在于点击范围的错误处理,导致未能正确生成包围范围数据。
原代码如下:
/// <summary> | |
/// 获取超链接解析后的最后输出文本 | |
/// </summary> | |
/// <returns></returns> | |
protected void UpdateHrefInfo() | |
{ | |
s_TextBuilder.Length = 0; | |
m_HrefInfos.Clear(); | |
var indexText = 0; | |
foreach (Match match in s_HrefRegex.Matches(originalText)) | |
{ | |
string replaceText = originalText.Substring(indexText, match.Index - indexText); | |
s_TextBuilder.Append(replaceText); | |
//s_TextBuilder.Append (string.Format ("<color={0}>", _href_Color)); // 超链接颜色 | |
var group = match.Groups[1]; | |
var hrefInfo = new HrefInfo | |
{ | |
startIndex = s_TextBuilder.Length * 4, // 超链接里的文本起始顶点索引 | |
endIndex = (s_TextBuilder.Length + match.Groups[2].Length - 1) * 4 + 3, | |
name = group.Value | |
}; | |
m_HrefInfos.Add(hrefInfo); | |
s_TextBuilder.Append(match.Groups[2].Value); | |
//s_TextBuilder.Append("</color>"); | |
indexText = match.Index + match.Length; | |
} | |
s_TextBuilder.Append(originalText.Substring(indexText, originalText.Length - indexText)); | |
//return s_TextBuilder.ToString(); | |
} |
主要问题在于,其中计算 『超链接里的文本起始顶点索引』中,直接拿原文进行计算,没有忽略富文本信息,上边提到过,新版 UGUI 已经不再包含富文本数据。
因此超链接问题修改相对比较简单,在此处筛除掉富文本信息,然后再取长度即可。
// 省略 ============= | |
int length = ReplaceRichText(s_TextBuilder.ToString()).Length; | |
var hrefInfo = new HrefInfo | |
{ | |
startIndex = length * 4, // 超链接里的文本起始顶点索引 | |
endIndex = (length + match.Groups[2].Length - 1) * 4 + 3, | |
name = group.Value | |
}; | |
// 省略 ============= | |
//Unity2019 富文本什么的顶点信息都没了,计算长度时剔除富文本 | |
private string ReplaceRichText(string str) | |
{ | |
str = Regex.Replace(str, @"<color=(.+?)>", ""); | |
str = str.Replace("</color>", ""); | |
str = str.Replace("<b>", ""); | |
str = str.Replace("</b>", ""); | |
str = str.Replace("<i>", ""); | |
str = str.Replace("</i>", ""); | |
str = str.Replace("\n", ""); | |
str = str.Replace("\t", ""); | |
str = str.Replace("\r", ""); | |
str = str.Replace(" ", ""); | |
return str; | |
} |
# 图文混排
这个问题跟超链接类似,都是由于 UGUI 不再记录富文本信息导致失效。
虽然知道了这点,但是由于图文混排操作更多,即使问题一样,修复图文混排还是要麻烦得多。
# 基础修复
来到绘制表情的方法,这儿位于 OnPopulateMesh,原本代码如下:
MatchCollection matches = Regex.Matches(text, "<quad.+?>"); | |
int diff = 0; | |
for (int i = 0; i < matches.Count; i++) | |
{ | |
EmojiInfo info; | |
Match numberMatch = Regex.Match(matches[i].Value, "[0-9]+"); | |
if (EmojiIndex.TryGetValue(numberMatch.Value, out info)) | |
{ | |
info.len = matches[i].Length; | |
emojiDic.Add(matches[i].Index, info); | |
diff += info.len - 1; | |
} | |
else | |
{ | |
info.len = matches[i].Length; | |
emojiDic.Add(matches[i].Index, EmojiIndex["0"]); | |
diff += info.len - 1; | |
} | |
} |
此处处在正式绘制之前,通过正则表达式,解析原本的文字内容,将表情标签剔出来,并生成对应对应表情数据放在一个字典中,以备后用。
出现问题的主要原因就在于原本的这个 matches[i].Index —— 既然是正则表达式,那么获取到的下标,自然是没有排除用于表情占位标签长度的,之前 UGUI 同样存储了对这些标签的处理数据还没事,现在 UGUI 数据中不在包含,获取的数据就会有问题。
因此,我合计了一下 <quad name = XX> 的长度,计算了一下各种组合可能的长度:
// 仅表情标签,不算表情 id 的长度 | |
"<quad name = >".Length | |
14 | |
//1 位表情 id 的表情标签长度 | |
"<quad name = 2>".Length | |
15 | |
// 两个连续 2 位表情,总共长度 | |
"<quad name = 22><quad name = 22>".Length | |
32 | |
// 两个连续表情,第二个表情坐标 | |
"<quad name = 22><quad name = 8>".IndexOf("<quad name = 8>") | |
16 | |
// 一个 2 位表情标签长度 | |
"<quad name = 22>".Length | |
16 | |
// 一个 1 位表情标签长度 | |
"<quad name = 8>".Length | |
15 | |
// 确认 Unicode 空格符长度 | |
"\u3000\u3000\u3000\u3000".Length | |
4 | |
// 混合表情,剔除第一个表情标签长度 | |
"bbbbb<quad name = 22>aaaaaa<quad name = 8>".Length-16 | |
26 | |
// 混合表情,第二个表情标签坐标 | |
"bbbbb<quad name = 22>aaaaaa<quad name = 8>".IndexOf("<quad name = 8>")-16 | |
11 | |
// 连续两个表情标签,剔除第一个表情标签后第二个表情标签坐标 | |
"<quad name = 22><quad name = 8>".IndexOf("<quad name = 8>")-16 | |
0 |
如此,找出一个比较共性的一点,使得计算时剔除 <quad name = XX> 的长度之后进行尝试性修改:
MatchCollection matches = Regex.Matches(ReplaceRichText(text), "<quad.+?>"); | |
int diff = 0; | |
// 表情富文本的长度 (除表情 id) | |
int richMarkLength = 14; | |
// 上一个表情 index | |
int lastEmojiIndex = 0; | |
for (int i = 0; i < matches.Count; i++) | |
{ | |
EmojiInfo info; | |
Match numberMatch = Regex.Match(matches[i].Value, "[0-9]+"); | |
int dicIndexId = matches[i].Index - lastEmojiIndex; | |
// 处理连续表情标签 | |
while (emojiDic.ContainsKey(dicIndexId)) dicIndexId += 1; | |
if (EmojiIndex.TryGetValue(numberMatch.Value, out info)) | |
emojiDic.Add(dicIndexId, info); | |
else | |
emojiDic.Add(dicIndexId, EmojiIndex["0"]); | |
info.len = matches[i].Length; | |
diff += info.len - 1; | |
// 处理多个表情,由于 Unity2019 去掉了富文本顶点之类信息,后续表情需要减去之前表情标签长度 | |
lastEmojiIndex += (richMarkLength+ numberMatch.Value.Length-1); | |
} |
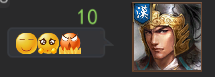
# 最后一位缺失
最后,可能会发现最后一个表情 (/ 文字) 无法显示,关键代码如下,根据注释意思,删除减掉的 4 个顶点代码即可。
//Last 4 verts are always a new line... | |
int vertCount = verts.Count-4; |
按照上述规则,表现看起来貌似基本上正常了。
# 包含额外富文本修复
但是后边发现,要是插入了其它富文本的信息,又会导致变成乱码了。

原因是上述方式虽然排除了表情标签的影响,但貌似并未剔除其它富文本标签影响 —— 说起来这个我还是后边才发觉。
为此可以在正式使用正则表达式,筛选表情标签之前,剔除富文本信息:
MatchCollection matches = Regex.Matches(ReplaceRichText(text), "<quad.+?>"); |
由于剔除也包括空格,因此这儿需要重新计算
以三个连续的表情为例:
//未剔除之前长度
"<quad name = 21><quad name = 22><quad name = 23>".Length
48
//剔除所有富文本数据后内容
ReplaceRichText(text)
"<quadname=21><quadname=22><quadname=23>"
//剔除所有富文本数据后长度
ReplaceRichText(text).Length
39
//一个表情标签的长度
"<quadname=23>".Length
13
//取第二位表情坐标
"<quadname=21><quadname=22><quadname=23>".IndexOf("<quadname=22>")
13
//仅表情标签,不算表情id的长度
"<quadname=>".Length
11
可得出修改方式:
- 将 text 进行正则表达式搜索之前,剔除富文本数据
- 将 richMarkLength 字段默认值改为 11
MatchCollection matches = Regex.Matches(ReplaceRichText(text), "<quad.+?>"); | |
int diff = 0; | |
// 表情富文本的长度 (除表情 id) | |
int richMarkLength = 11; |
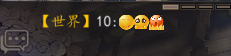
修改代码后,以连续三个表情为例,正常聊天频道表现正常,主界面额外聊天信息展示文本内容为:
"<color=#ffc800>【世界】</color>10:<quad name = 21><quad name = 22><quad name = 23>"
效果:
# 文字竖行排版功能问题
我们项目中叫做 『VirticalText』(感觉命名也错了,不是应该 VerticalText 吗?)
这份代码是通过操作 Text 旋转顶点实现竖行排版的,这份代码直接没法跑,报错了。
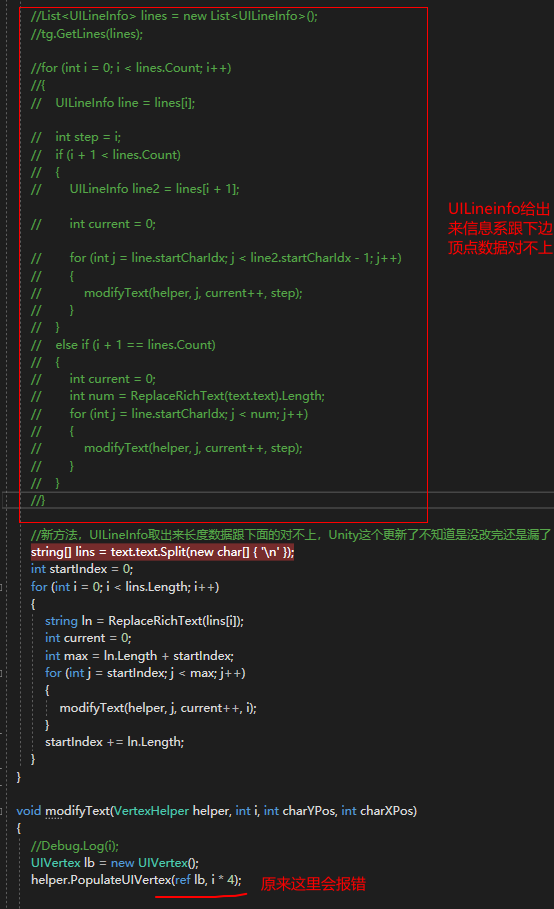
经过检查,发现同样是新版 Unity 的 UGUI 顶点数据问题导致,而且虽然 UGUI 内部不存储富文本数据了,但是这里非常不可思议的是,同样从 UGUI 系统内部获取的 UILineInfo 竟然包括了换行符!
然后使用 UILineInfo 给出的数据去调用 VertexHelper PopulateUIVertex 获取文字 UIVertex 就会报下标错误。
由于 UILineInfo 数据包括了换行符,顶点数据里边却不包括,就导致了最终的取值报错 —— 都是 UGUI 的数据,这完全整得 UGUI 自己的内部数据都不一致了,不确定是 UGUI 更新漏了,还是故意这样设计。
反正我的处理方式是,直接把老的那坨以 UILineInfo 作为数据源的方法去掉,自己写了一块直接通过字符串解析来解决。
首先,直接通过 『\n』 这个通用换行符进行 Split 获取文字行数,理论上跟 UILineInfo 数量一致。
然后循环修改,注意在取每一行文字的时候,同样增加筛除富文本数据判断即可。
效果如下:

