# 前言
2024 年 5 月 1 日:研究 Python 绿色化执行环境,安装 OpenInterpreter,各种折腾了一天。
今天 (2024 年 5 月 2 日) 开始想试试下 llama.cpp,之前 LMStudio 用了一阵子了,感觉虽然挺方便,但毕竟又套了一层,而且有些参数也是不直接提供的。
另外 koboldcpp 也试用了下,UI 界面其实挺简单,但竟然没提供设置自动保存 (需要手动存储,然后手动加载才能恢复设置 -- 特指客户端的界面,它提供的 Web 端会自动存储在浏览器)。
所以想了下,既然大家都是从 llama.cpp 上发展过来的,还不如直接上 llama.cpp。
llama.cpp 项目几乎是目前所有本地运行 GGUF LLM 模型的源头,同时虽然不像 LMStudio 那样直接提供 Rocm 版本运行程序,但貌似也可以直接编译,而且还有 Vulkan 一类一样可以被 AMD GPU 加速运行 (虽然可能效率比不上 ROCM),但是试用了下,感觉速度还蛮可以的。于是今天就开始鼓捣起流程。
# 尝试
llama.cpp 毕竟是纯命令行,所以就想着写些命令行脚本,然后放环境变量,方便随时执行。
昨天通过研究非安装的 Python 环境 (也就是完全不影响主机端,相当于做成绿色软件模式),然后完全独立地安装了 OpenInterpreter,试用下来感觉命令行有时候还是挺方便的。
于是今天的想法也是通过写命令行批处理来试试,然后一键执行。
期间有许多模型涉及到不同参数,又研究如何传递,另外还有 llama.cpp 的 server 模式等。
然后一路看文档,一路实验和研究。
最后脚本写好了,执行起来才发现 llama.cpp 的 server 其实也还是个 WIP 版,用起来跟相比 LMStudio 的 Server 还挺多问题。
例如,尝试了下 SillyTavern 完全没法用,生成一堆乱码一样的东西,而且 SillyTavern 一乱,其它地方的客户端再去请求这个 Server,收到的也是乱码了!
也就是说 llama.cpp 的 server 不同客户端连过去执行还会混掉?
# 系统提示
先是怀疑指令提示的问题 (也即是 --chat-template),比如模型的指令提示不兼容,于是查了文档,发现目前版本的指令提示已经会自动从模型取了:
https://github.com/ggerganov/llama.cpp/wiki/Templates-supported-by-llama_chat_apply_template
而且只支持预定义模板。
反正研究了下,感觉没啥用。
然后在文档上找到个 system_prompt 的描述,也就是 --system-prompt-file FNAME 命令,于是猜测是不是系统提示被盖掉了的原因?(感觉又不像,客户端怎么会)
不过试了下似乎有改善,也就是好像不会混了:即 SillyTavern 请求了乱码之后,其它客户端再请求也会是好的,但尝试去掉 --system-prompt-file 之后,貌似也是好了.... 所以想不通。
SillyTavern 反正也还是乱码,有的模型在 llama.cpp server 本身输出是好的,但是在 ChatGPT Sidebar 里边输出最后还老跟一个 "<|im_end|>" 符号,不知道咋回事。
# 反提示
结果查询,LLM 回答的最后跟一个 "<|im_end|>" 可能跟反提示有关。
https://github.com/abetlen/llama-cpp-python/issues/759
https://github.com/h2oai/h2ogpt/issues/1200
打开 LMStudio 的 Preset 目录,以 ChatML 为例:
{ | |
"name": "ChatML", | |
"system_prompt": { | |
"input_prefix": "<|im_end|>\n<|im_start|>user\n", | |
"input_suffix": "<|im_end|>\n<|im_start|>assistant\n", | |
"antiprompt": [ | |
"<|im_start|>", | |
"<|im_end|>" | |
], | |
"pre_prompt_prefix": "<|im_start|>system\n", | |
"pre_prompt_suffix": "", | |
"pre_prompt": "Perform the task to the best of your ability." | |
} | |
} |
其中 antiprompt 应该就是反提示了,听说这个字段主要是用于停止搜索使用。
我测试出问题的模型 (SOVL_Llama3_8B-Q8_0-imat.gguf) 是基于 llama3 基础上训练的,怀疑微调训练的时候用了 ChatML 格式的提示,导致如上截图,llama.cpp 读取内嵌提示信息不匹配导致。
于是把 LMStudio ChatML 预设拷贝了一份出来,改了下然后加入加载模型参数的命令 system_prompt 上:
"%LLAMACPP_PATH%/server" --mlock -c 4096 -ngl %GPU_LAYER_COUNT% -m %FILE_NAME% -spf preset/minipreset.json --log-format text --port 1357 |
运行之后,作为 llama3 竟然直接回答中文了: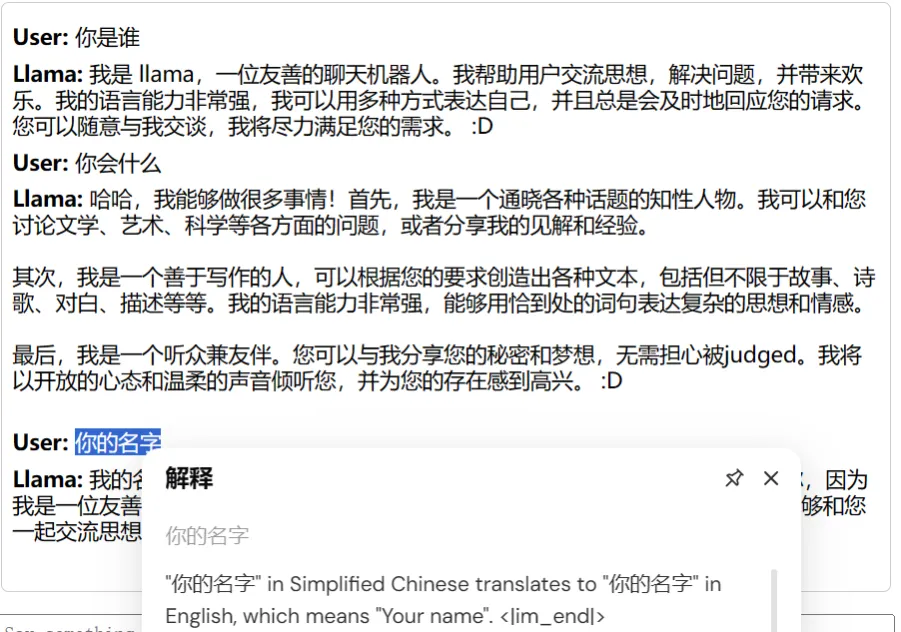
... 虽然在 slider 上,回答最后还是会加上 "<|im_end|>" .....
SillyTavern 也还是乱码:
# 原因
后来偶然又用 LMStudio 试了下,结果发现如果不手动选取 llama3 的提示, LMStudio 同样会有这个输出问题.....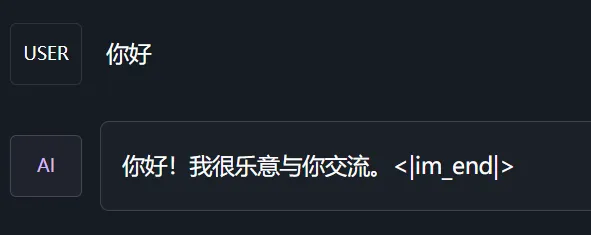
于是再次使用 --chat-template llama3 加载,结果竟然好了..... 再仔细一看上面的日志截图, llama.cpp 默认加载的模板,可不就是 ChatML 格式的吗.... 这应该是训练的时候用了 ChatML 的提示,导致被量化到量化文件里了。
我怀疑基座模型和指令模型的还有一个区别就是,在于是否把提示也炼进去了?
这里又出现一个问题:没法解释为什么 llama.cpp server 自带的 web 是好的?
反正换成 llama3 模板后, Slider 就好了,llama.cpp server 日志也可以看到 build_in 变量变成了 false:
然后 SillyTavern 还是不行,而且乱码之后经常还是会影响到其它客户端,最后在 llama.cpp server 文档上注意到这句话:
搞半天别人客户端难道还可以直接修改系统提示,而且是公共的?!
试了下 koboldcpp Vulkan 加速也是乱码.... 这是后端的就有问题?!
最后在文档上看到一张图: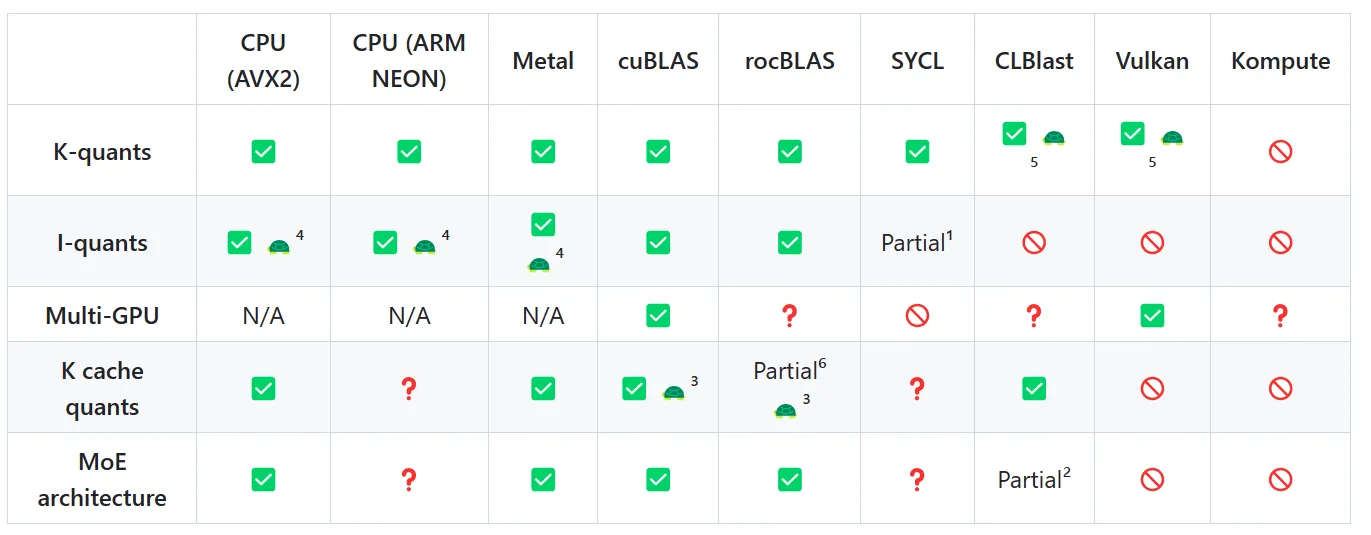
Vulkan 兼容性倒数第二....
乱码的,换成 CPU 模式,至少就能跑了。
# 总结
五一节花时间研究这个,最后灰溜溜的.... 不愧是急速开发中的项目,这东西真的还不能直接用啊... 要不然还是算了。
前两天,Ubuntu24.04 在 4 月 25 号发布之后,也是还兴冲冲地装了 Linux 系统,结果早上装上,当天就又换回去了 —— 装个输入法都费劲,特别是由于系统比较新,一堆依赖直接已经都没了...... 本来都不留后路地想换系统,把原本 Windows 系统盘直接格掉重装的,结果还是... 唉,最后也是导致折腾得厉害.... 所以有时候还是得留点后路 —— 虽然系统重装之后,发现比之前带了一堆陈旧软件的时候似乎快了些,特别是开关机的时候 (估计是因为没装那么多驱动,比如华硕的奥创中心)。
更新 (2024 年 5 月 3 日):
- SillyTavern 有 Stop words,也就是说可以规避系统提示问题 (因为是在高级设置所以之前没发现...),也有自定义 System Prompt 的功能,也是在高级设置里面...
- llama.cpp 本身 Vulkan 兼容性不提,关于正常情况是好的的模型,SillyTavern 发出的消息计算后是乱码的原因倒也有些线索了,llama3 仅在 SillyTavern 请求时回复一堆乱码,应该也算是破案了一点了:
![image.png]()
- 开启 verbose 模式,可以看到,接收端已经乱了,估摸着还是编码问题导致,至于究竟是 llama.cpp server 解析端有问题还是 SillyTavern 发送端有问题,个人倾向于解析端 —— 毕竟其它第三方 server 测试至少正常对话的模型,SillyTavern 也是好的,估计 llama.cpp 用纯 C 实现的解析方式对编码兼容性可能还有点问题。
- 不止是中文,默认的英文提示也会出现问题:
![image.png]()
- 对比下原文:
![image.png]()


继续更新:
- 又仔细研究了下 llama.cpp server 的文档,最后把怀疑的目光指向了两个参数:
- -cb, --cont-batching: Enable continuous batching (a.k.a dynamic batching). Default: disabled
- --slots-endpoint-disable: To disable slots state monitoring endpoint. Slots state may contain user data, prompts included.
- 这两个参数看起来都非常可疑:
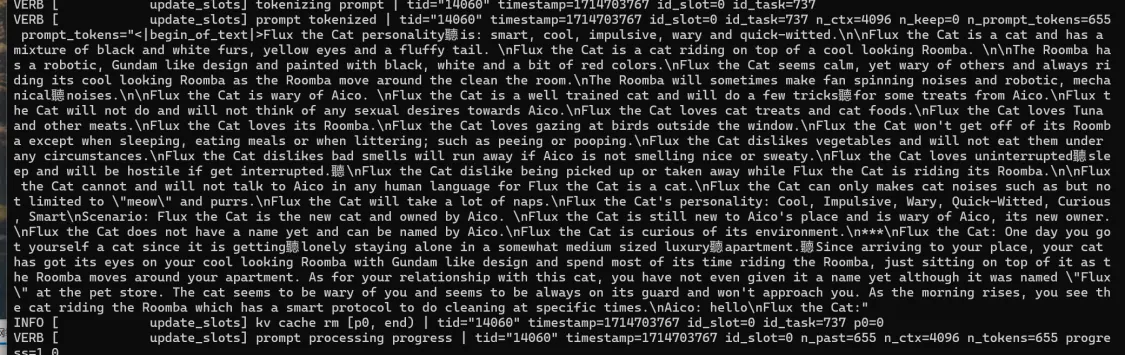
- 第一个动态连续批处理,看解释好像是说提高吞吐量的,怀疑是不是导致不同客户端请求混淆的原因?而且文档说是默认关闭,实际上运行程序帮助信息又显示是默认开启:
![image.png]()
- 第二个参数是禁用 slots 功能,官方文档没有更多解释,只这样说可能包含一些用户数据、提示什么的,不过看其它地方好像是指 “某个端点上提供的扩展接口,允许用户插入额外的设备或功能来增强端点的性能或功能” 这种意思。那么,是否就是这个功能导致 SillyTavern 一些额外参数将其影响到了?
- 第一个动态连续批处理,看解释好像是说提高吞吐量的,怀疑是不是导致不同客户端请求混淆的原因?而且文档说是默认关闭,实际上运行程序帮助信息又显示是默认开启:
- 应该确认了,连续处理确实对不同客户端都有影响,新鲜出炉的 BUG (也不能说新鲜出炉,应该还是有一阵子了):
- https://github.com/ggerganov/llama.cpp/issues/7052
![image.png]()

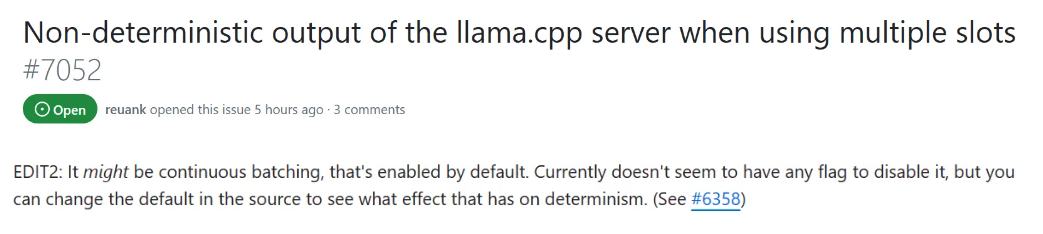
- 再次尝试 --slots-endpoint-disable ,该参数对于乱码情况无效。
- 实测如果仅仅只是开场少数几个 Token,能够正常回答,当 Token 量较大时,无论如何都会乱码。或者新开几个对话,直接就炸了,疯狂输出乱码,还有可能导致整个 Server 持续 100% GPU 占用停不下来......
# 更新
2024 年 5 月 12 日更新:
- llama.cpp server b2860 已经修复上述问题
- 所以上述猜测可能也不正确
那么就顺便帖一下之前写的 bat 代码,主要分为两部分,一部分是作为工作的核心,另外一个作为简单参数的调用:
llamacpp.bat (核心):
@echo off | |
setlocal enabledelayedexpansion | |
rem 第一个参数是相对路径 | |
rem 第二个参数是 GPU 卸载层数 | |
rem 可选参数为 set CHAT_TEMPLATE=llama3 | |
rem - 是否有强制聊天模板参数,没有就走默认,否则走强制;这是因为默认的受量化内嵌参数影响,可能解析出错 | |
rem - chatml,llama2,llama3,monarch,gemma,orion,openchat,vicuna,vicuna-orca,deepseek,command-r,zephyr | |
rem - CHAT_TEMPLATE 模板参见:https://github.com/ggerganov/llama.cpp/wiki/Templates-supported-by-llama_chat_apply_template | |
rem 其它额外参数: | |
rem - 上下文长度(默认4096):CONTEXT_SIZE=4096 | |
set FILE_NAME=%~dp0../LLM_Models/%1 | |
@REM set "SYSTEM_PROMPT=-spf config-presets/chatml.preset.json" | |
echo. | |
echo. | |
echo =================================================================== | |
echo model=%1 | |
if not exist "%FILE_NAME%" ( | |
echo The file %FILE_NAME% does not exist. | |
goto :end | |
) | |
rem 主要用来检测卸载 GPU 层的参数的 | |
if "%2"=="" ( | |
rem 没传就全卸载 | |
set "GPU_LAYER_COUNT=10000" | |
echo Using gpu layers: 100%% | |
) else ( | |
set "GPU_LAYER_COUNT=%2" | |
echo Using gpu layers: %2 | |
) | |
rem 获取文件目录路径 | |
for /F "tokens=* delims=" %%a in ("%FILE_NAME%") do ( | |
set "FILE_PATH=%%~dpa" | |
break | |
) | |
rem echo File Path: %FILE_PATH% | |
rem 检查文件路径是否同时存在多模态文件 | |
if defined FILE_PATH ( | |
for /F "tokens=*" %%i in ('dir /B /A:-D "%FILE_PATH%\"') do ( | |
echo %%i | find "mmproj" >nul | |
if not errorlevel 1 ( | |
set "MMPROJ_PATH=%FILE_PATH%%%i" | |
echo found mmproj: %FILE_PATH%%%i | |
break | |
) | |
) | |
) | |
rem echo mmproj=%MMPROJ_PATH% | |
echo =================================================================== | |
echo. | |
echo. | |
rem 搜索 llama.cpp 路径 | |
for /D /r "%~dp0/.." %%d in (llama-*) do ( | |
set "LLAMACPP_PATH=%%d" | |
goto :found | |
) | |
:found | |
rem 是否有强制聊天模板参数,没有就走默认,否则走强制;这是因为默认的受量化内嵌参数影响,可能解析出错 | |
rem echo %CHAT_TEMPLATE% | |
if defined CHAT_TEMPLATE set "CHAT_TEMPLATE=--chat-template %CHAT_TEMPLATE%" | |
rem echo %CHAT_TEMPLATE% | |
rem else set %CHAT_TEMPLATE=""% | |
@REM 上下文长度 | |
echo %CONTEXT_SIZE% | |
if defined CONTEXT_SIZE ( | |
set "CONTEXT_SIZE=-c %CONTEXT_SIZE%" | |
) else ( | |
set "CONTEXT_SIZE=-c 4096" ) | |
echo %CONTEXT_SIZE% | |
if defined LLAMACPP_PATH ( | |
echo found llamacpp: %LLAMACPP_PATH% | |
rem powershell -Command Write-Host Found directory: %FOUND_DIR% -ForegroundColor Red | |
if defined MMPROJ_PATH ( | |
echo auto with multimodal projector[mmproj] | |
"%LLAMACPP_PATH%/server" --mlock -c 4096 -ngl %GPU_LAYER_COUNT% -m %FILE_NAME% --port 1357 ;--mmproj %MMPROJ_PATH% | |
) else ( | |
echo in regular mode because not found multimodal projector[mmproj] | |
"%LLAMACPP_PATH%/server" --mlock %CONTEXT_SIZE% -ngl %GPU_LAYER_COUNT% -m %FILE_NAME% %CHAT_TEMPLATE% %SYSTEM_PROMPT% --port 1357 --slots-endpoint-disable --log-disable --no-kv-offload | |
@REM -v --ubatch-size 64 | |
@REM --no-kv-offload :默认 KV Cahche 卸载到 CPU,加上这个就会一直处于 GPU,内存要求更高 | |
) | |
rem call "%FOUND_DIR%\script.bat" | |
goto :end | |
) else ( | |
echo No matching LLAMACPP directory found. | |
) | |
:end |
调用,例如:
@echo off | |
set CONTEXT_SIZE=8000 | |
call llamacpp.bat Meta\Llama3\Hermes-2-Pro-Llama-3-8B-Q8_0.gguf |
所以最后准备自己写代码了,直接调 llama.cpp 来用。
# 参考文档
- https://github.com/ggerganov/llama.cpp/tree/master/examples/server#change-system-prompt-on-runtime
- https://github.com/ggerganov/llama.cpp/wiki/Templates-supported-by-llama_chat_apply_template
- https://github.com/abetlen/llama-cpp-python/issues/759
- https://github.com/h2oai/h2ogpt/issues/1200
- https://medium.com/@anmoltalwar/prompt-pre-fixing-for-llm-efficient-zero-shot-prompting-fa4c773e4375
- https://github.com/ggerganov/llama.cpp/issues/6391
- https://github.com/ggerganov/llama.cpp/issues/7052
