
# 前言
本篇包含原书第五章和第六章,主要讲了 .NET 内存分区和内存分配方式
- 小对象通过指针快速分配 (多数情况下)
- 大对象通过空闲列表分配 (因此最好避免)
并提出了一些优化方式:避免分配,包括显式和隐式分配等
# 第五章 内存分区
# 分区策略
总体上有:
- 大小
- 生存期
- 可变性
- 类型
- 种类
简单来说,.NET 根据『大小』和『生存期』作为分区策略。
# 按大小分区
.NET 根据大小处理不同对象,分为两类:
- 小对象堆 (SOH):所有小于 85000 字节的对象在此分区创建
- 大对象堆 (LOH):所有大于或等于 85000 字节的对象在此创建
区别在于,默认情况下小对象堆在 GC 回收后会进行压缩,而大对象堆默认不会。
对齐方式
- 32 位:SOH 4 字节对齐,LOH 8 字节对齐
- 64 位:SOH 和 LOH 均 8 字节对齐
注 1:Mono 5.4 单个对象大小阈值为 8000 字节
注 2:具传言所说,85000 字节是微软内部测试实验而选出,但并未经证实。
注 3:计算的是对象引用的浅表大小 (即实际大小),而非引用对象的大小。对大数组作为字段时,只是对其一个小引用。
# 小对象堆
使用频率最高的内存区域,通常其中分配对象会在数量级上超过位于 LOH 的对象数量。
因此将其划分为更小的分离部分,即常规意义上说的分代:0、1、2 代
# 大对象堆
有时候被称为第三代,或者是被第三个索引引用 (位于 0、1、2 这三代之后)
- 不过从回收器角度看,LOH 中的大对象在逻辑上属于第二代,因为它们仅在第二代被回收时才被回收。
处于其中的常见对象:
- double 数组:等于或大于 1000 个元素时就会在 LOH 中进行分配 (例外)——[注意是 32 位运行环境]
- 原因与内存对齐方式有关,double 占 8 个字节,而 32 位环境下,大对象堆 8 字节对齐,访问消耗更低
- 1000 个阈值是为了避免内存碎片
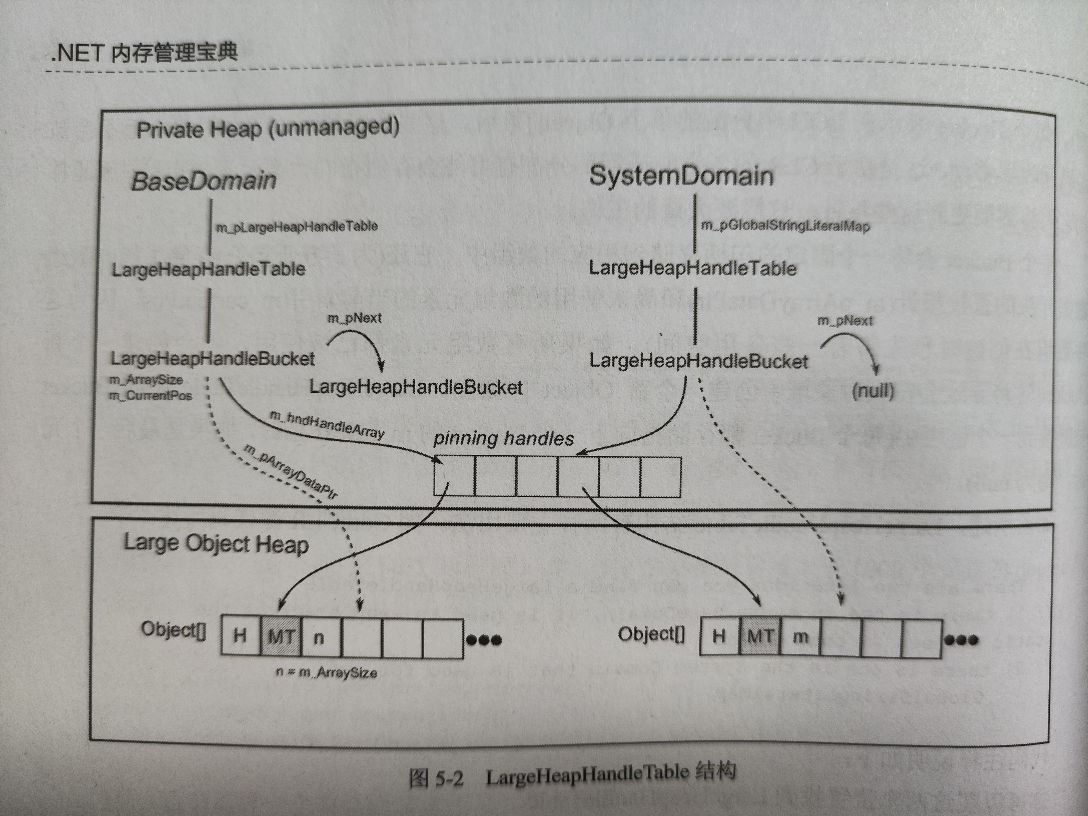
- 内部 CLR 数据:LargeHeapHandleTable,该结构管理在大对象堆中分配用于内部用途的对象数组。
- 每个域的静态成员,至少包含一个 bucket
- 全局字符串文字映射 (StringIntern)-GlobalStringLiteralMap
注:大对象堆默认不压缩,注意会产生内存碎片
# 按生存期分区
如前所述,小对象堆可能存在大量对象,因此在决定再根据生存期分成若干部分,即『分代垃圾回收 (Generational Garbage Collection』
做法有两种:
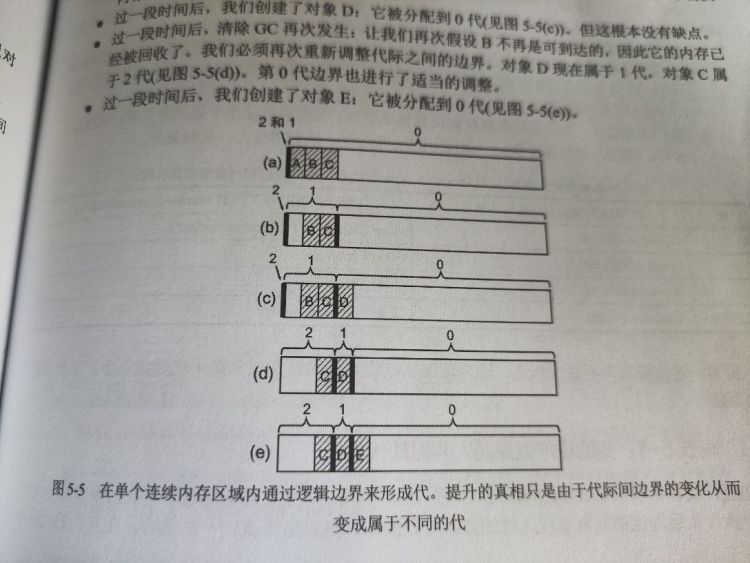
- 提升复制,为名为 0、1、2 的代提供三个单独的内存区域,回收年轻代对象时,存活对象被复制到老一代内存区域(会有复制开销)
- 按地址边界在逻辑上定义代,即在单个连续内存区域内通过逻辑边界来形成代,避免复制开销(.NET 采用的方式)
# 记忆集 (remembered sets)
标记阶段使用可达性分析进行。
如何做到只回收『年轻』一代的?
- 从根开始遍历,忽略此代之外的引用
同时存在跨代引用问题需要处理:
- 从年轻到老:最近创建对象可能引用已存在老对象
- 从老到年轻:老对象可能直接设置包含新创建对象的引用
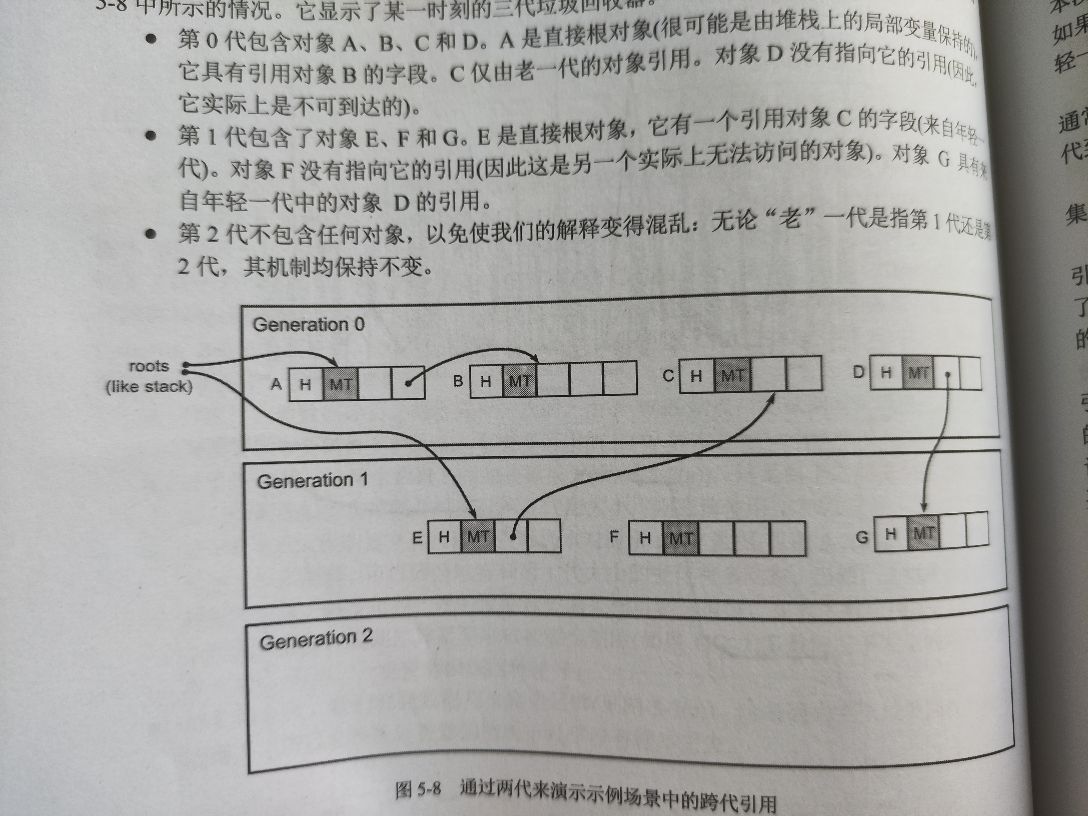
记忆集是一组记忆从老一代到年轻一代的引用、用于跨代回收的集。然后在标记阶段对它们进行简单的审查。
- 在创建此类引用时记住它,主要发生于字段分配期间
- 在 Mutator.write 操作插入这个指令会带来很大开销,不过 JIT 编译器可以从 IL 代码了解信息 (是否将托管对象的引用存储到另一个托管对象的字段中),并在生成汇编代码时可选是否生成对应代码 (.NET 运行时采用的方式)
如果年轻代引用老年代,也需要如此实现记忆集,这并不容易。因此 .NET 采用了更简单的决定:回收某一代同时也意味着回收比它更年轻代的对象。
- 仅回收第 0 代
- 回收第 0 代和第 1 代
- 回收所有第 0 代、第 1 代和第 2 代以及大对象堆 (完全垃圾回收)
# 卡表 (Card Tables)
.NET 有三代,因此可能的跨代引用数量可能很大。将一个记忆集作为每个跨代引用的幼稚回收管理会带来过大开销。
卡表即是对记忆集的优化:
- 将老一代拆分成恒定大小区域 (具有给定字节数的连续内存区域)
- 当某个地方将对象 C 分配给对象 E 字段时,计算 E 的卡,并将卡标记为 dirty,此后该卡中所有对象都被视为附加的根
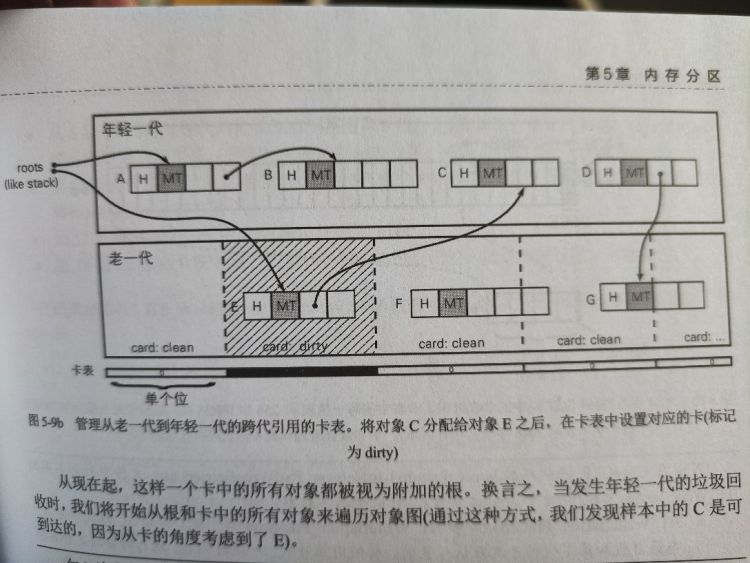
这显然也会有开销:即使只有一个从老一代对象到年轻一代的引用,也必须访问卡中所有对象并遵循它们的引用。不过,这也是性能和准确性之间的权衡。
注意:
- 如果一张卡片很小,小到做多只能包含一个对象,那么我们最终会得到一个典型记忆集方法。
- 如果一张卡片很大以至于覆盖了整整一代,那么最终会变成遍历整个对象图的方法。
在 .NET 运行时 (64 位) 中,一张卡对应于 256 个字节,每个这样的卡都由一个位标志表示。
- 1 字节能表示 8 倍 256 字节,即 2048 字节的存储区域。
- 卡片被分为 32 个元素,称为卡片字,意味着卡片字是 4 字节宽的 DWORD 类型 (ulong)。单个卡片字表示 8192 字节。
# 卡包 (Card Bundles)
卡表优化了记忆集的使用,但是扫描依然会带来较大开销,此外卡表可能比较稀疏。
因此增加了另一个级别的观察:
- 一个卡字将多个卡组合在一起,而一个卡包字将多个卡字组合在一起
- 卡包字设计密度更高,可覆盖更大内存区域
- 首先扫描卡包以查找 dirty 的大区域,再对其中卡表进行更精确扫描。
# 按物理分区
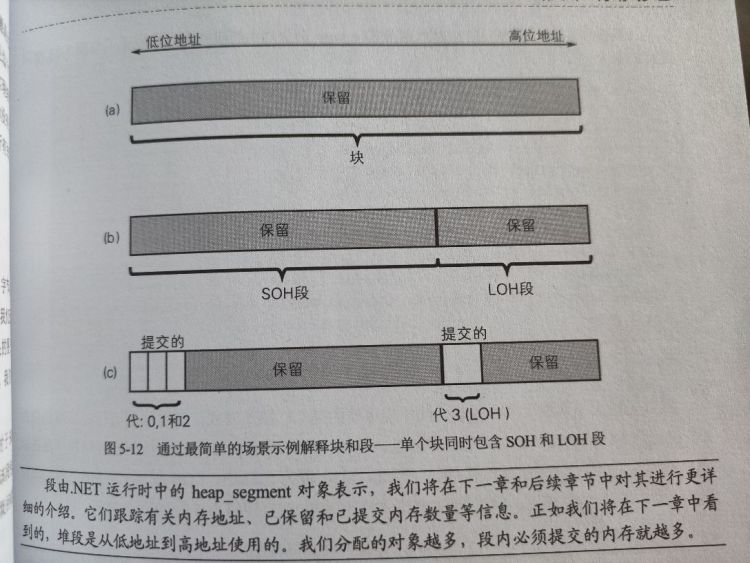
从物理上讲,托管堆由一组堆段组成:一个段要么属于 SOH 要么 属于 LOH
- 注:对于 SOH,如果存在多个段,那么只有一个称为『临时段』的包含第 0 代和第 1 代,其它段都是第 2 代的段。
堆段从低地址到高地址使用
- .NET 运行时尝试为初始段分配 (保留) 单个连续内存块
- 为 SOH 和 LOH 创建两个单独的段
- 第 0、1、2 代通过提交一些指定数量内存在 SOH 段内创建,LOH 也提交一定数量内存
# 段和堆解析
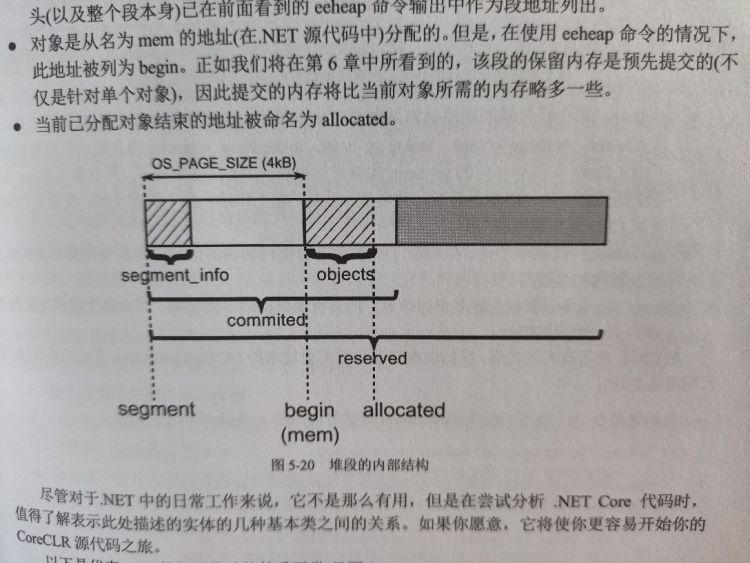
段是托管堆的物理表示,每个 SOH 和 LOH 都具有以下结构:
- 在开始处存储段信息 (heap_segment 类的一个实例)
- 对象从名为 mem 的地址分配
- 当前已分配对象结束的地址被命名为 allocated
# 段重用
连续创建和删除段可能导致碎片问题,特别是 32 位虚拟地址空间有限的情况。
因此引入更智能的段处理:虚拟机囤积 (VM Hoarding)
- 与其完全释放空段,不如将其存储 (囤积) 以供以后使用
即:
- 整个段内存将保持保留
- 该段大部分内存被取消提交 (不消耗物理内存),只有少量信息 (如段信息) 保持提交状态
- 在一个可重用列表记录,当需要新段时,首先检查
注 1:在 64 位执行引擎中,由于虚拟地址空间大很多,囤积相对就没那么重要了。不过,由于在非常动态场景中,有许多段被创建和销毁时,重用速度更快,因此在 64 位下段重用也是值得的。
注 2:默认情况下 .NET 会禁用段囤积功能 (System.GC.RetainVM)
# 第六章 内存分配
分配器 (allocator) 概念:负责提供指定大小内存,在此抽象层次上,分配器并不关心内存中需要存储的是哪种类型对象,只需提供正确数量字节空间即可。
.NET 托管环境会预先分配连续内存块,比每次创建对象都向操作系统请求更快,且可以简化内存分配机制。
对象分配发生于:
- 对于 SOH:分配发生于 0 代,位于一个暂留段。
- 对于 LOH:分配发生在多个 LOH 段中的一个。
每次分配一个大对象时会考虑整个 LOH,而分配小对象仅考虑暂留段。
有两种实现分配器方法:
- 循序分配和自由列表
- .NET 同时使用了两者
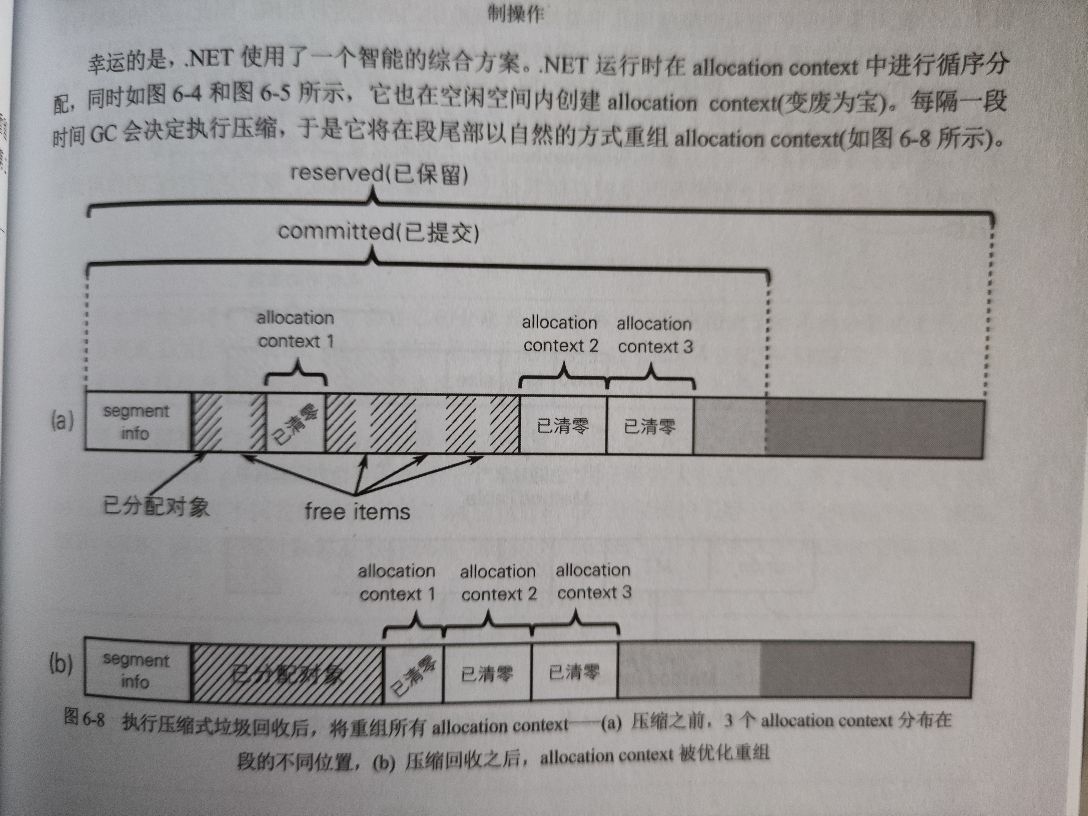
# Bump Pointer 分配
即采用循序分配的一种模式,分配指针指向已分配对象末尾,提前清零区域 (allocation context) 前端,分配内存时,仅需要往提前清零区域移动指定字节即可。
- 注:allocation context 是每个线程独占的
# 空闲列表分配
当运行时要求 GC 分配给定大小内存时,其在一个空闲列表中搜索,以找到一块足够大的空闲空隙。
- 最佳匹配:找到最匹配所需空间内存
- 最先匹配:找到第一块能满足需求的空闲内存
# 创建新对象
CIL 代码:newobj
- 如果对象超出大尺寸阈值 (在 LOH 中创建),或者其有终结器则使用通用且稍慢的 JIT_New 函数
- 否则使用较快的辅助函数
例外的是创建数组:newarr,用于创建数组对象的优化版本
# 小对象堆分配
基本通过 bump pointer 分配到到 allocation context 中。
- 注:若 allocation context 无法满足所需大小,或对象带终结器,则将回退到调用更通用的 JIT_NEW 函数,此函数包含完成分配的慢速分支代码。
慢速分支逻辑:
- 首先尝试使用暂留段中已有的未使用空间
- 尝试使用空闲列表找到一块合适的内存空隙,用其创建一个新的 allocation context
- 尝试调整 commited 内存中的分配限制位
- 尝试从 reserved 内存中提交更多内存,并调整位于其内部的分配限制位
- 若上述操作皆失败,则触发垃圾回 (收回收根据具体情况执行多次)
- 若上述依然失败,则触发 OutOfMemoryException
# 大对象堆分配
主要使用空闲列表分配机制,并在段空间末尾使用一种简化的 bump pointer 技术 (不使用 allocation context)
LOH 分配器总是采取与 SOH 慢速分支类似的方法。
- 首先尝试使用未使用的现有空间
- 尝试使用空闲列表为对象寻找一个合适的内存空隙
- 在每个包含 LOH 段中:
- 尝试调整 commited 内存中的分配限制位
- 尝试从 reserved 内存中提交更多内存,并调整位于其内部的分配限制位
- 若上述操作皆失败,则触发垃圾回收 (回收根据具体情况执行多次)
- 若上述依然失败,则触发 OutOfMemoryException
同时,由于 LOH 没有 allocation context 机制,因此分配完成后还需对对象内存清零,而大对象内存清零本来也是一段耗时过程。
因此 LOH 分配开销远大于 SOH 分配。
# 堆再平衡
略
# OutOfMemoryException 异常
已经触发垃圾回收器
- 此时再触发垃圾回收没什么用,倒是可以考虑显示触发 LOH 压缩后再触发一次 GC
分配器无法准备所需大小的内存区域
- 虚拟内存已耗尽 (32 位),主要由于内存碎片导致
- 物理后备存储 (包括物理内存和交换内存) 已耗尽
改进:
- 少分配一些对象
- 使用对象池
- 使用 VM Hoarding
- 编译为 64 位程序
# 堆栈分配
堆栈分配只需要移动 stack 指针,不会造成任何 GC 开销。
在满足条件的情况下,值类型将在堆栈上分配。
除此之外,也可以通过 stackalloc 显示在堆栈分配内存。其返回一个指针,可使用指针或 span<> 操作,其有两个好处:
- 销毁以这种方式创建的对象与销毁堆栈上其它对象的速度一样快,无需使用堆分配器,不会进入分配决策树的慢速分支,也完全不需要 GC
- 由于 stack frames 不会在内存中移动,因此此类对象的地址也被隐式固定,可以安全将指针传递给非托管代码。
stackalloc 被转换为 CIL 指令 localloc
注:stackalloc 仅能用于分配一个 unmanaged_type 元素类型的数组。
- 基元类型
- 枚举类型
- 指针类型
- 所有非构造类型且仅包含 unmanaged_type 字段的用户自定义结构
无法显示释放 stackalloc 分配的内存,方法结束时将隐式释放。
# 避免分配
# 显式的引用类型分配
可以认真评估,在特定情况下,是否真的有必要在堆上创建引用类型对象?
- 通用场景 - 考虑使用结构
- 例如数据不存储任何基于堆的数据内部
- 元组 - 使用 ValueTuple 代替
- 注 1:Tulpe 和匿名类型都是引用类型
- 注 2:值元组有种称为解构 (deconstruction) 的特性,允许直接将方法返回元组赋值给元组,还可以使用弃元 (discarding) 显示忽略不感兴趣的元素
- 小型临时局部数据 - 考虑使用 stackalloc
- 结构数组依然会分配在堆上,可以使用 stackalloc 使其分配于堆栈
- stackalloc 缺点在于可能引发堆栈溢出异常
- 如果想使用并希望百分百不会引发堆栈溢出异常,可尝试使用 RuntimeHelpers.TryEnsureSufficientExecutionStack () 或 RuntimeHelpers.EnsureSufficientExecutionStack () 方法
- 创建数组 - 使用 ArrayPool
- ArrayPool 提供可重用托管数组池的专用方案 (包含在 SystemBuffers 中)
- 其管理指定类型的不同大小的数组集,并将数组分组到不同的 bucket 中
- 通过静态属性 ArrayPool
.Share 可获得此类型的默认数组池:当需要时调用 Rent,不需要时调用 Return 方法归还(获取的数组长度可能大于指定长度,不低于指定值,从 16 开始按倍数提前确定好) - 注 1:内部使用了相当复杂的缓存技术,并针对多线程有处理,如使用了 TLS (thread local storage)
- 注 2:位于 ArrayPool 的数组将永久存活,因此若是短时间临时使用需要谨慎考虑
- Streams - 使用 RecyclableMemoryStream
- 注:若程序需要密集使用 MemoryStream,还可以考虑使用 System.IO.Pipelines,比 Stream 更高效,内存分配更少
- 创建大量对象 - 使用对象池
- 返回 Task 对象的异步方法 - 使用 ValueTask
# 隐式的分配
- 委托导致的分配
- 创建一个新的委托会导致一次隐式分配
- C# 编译器对 lambda 有一个重要优化:如果表达式未捕获任何数据,编译器会生成额外代码,将委托实例作为静态字段缓存,使其仅在第一次分配一次
- 装箱
- 在需要使用对象 (引用类型) 的地方使用值类型
- 以接口类型使用值类型实例
- 避免方式是最好使用泛型、泛型约束
- 调用 valueType.GetHashCode () 和 valueType.ToString () 但值类型未重写
- 调用 valueType.GetType () 一定会将值类型装箱
- 从一个值类型的方法创建委托时一定会将其装箱 (值类型实例需要被引用)
- 闭包 (closures)
- Yield Return (迭代器)
- 参数数组 (params)
- 串联多个字符串
# 类库中各种隐式分配
- System.Generics 集合
- LINQ - 委托
- LINQ - 创建匿名类型
- LINQ - 枚举
注:可以使用自动将 LINQ 查询重写成常规过程式代码的类库,可以既享受 LINQ 查询的好处,又避免分配的缺点。
- 如 roslyn-linq-rewrite
- LinqOptimizer
