
# 前言
本篇包含原书的第三章和第四章,第三章主要讲了一些测试工具使用,我自己也看得也比较囫囵吞枣 (毕竟个人是搞 Unity3D,这块多数工具基本都是没用的,当然部分理论依然还是可以参考的)。
其次是第四章的 .NET基础知识 ,这一章名字说是基础知识,实际上还是比较深入的,比如各个字段的内存区域、详细描述了为什么值类型 更快 等等。评价是 比较重要 。
# 第三章 内存测量
# 尽早测量
与其过早地专注于优化,不如先测量评估一下我们是否有这方面的需求。
# 开销和侵入性
开销:额外消耗
侵入性:游戏应用程序本身功能
# 采样与跟踪
跟踪:诊断数据在特定的、被关注的时间触发时收集 (基于事件),优势是具有数据精确性。
采样:可以接受数据精度丢失,仅间隔一定时间搜集 (基于时间) 采样频率越低,从测量中得到的数据就越不精确。
# 调用树
- 独占:仅包含该特定函数的值。
- 包含:测量该特定函数的值及其所有子函数的测量值的总和。(在该函数时间、它所调用的所有其它函数的时间,及调用的所有函数等时间总和)
浏览这个树,我们可以很快找出最慢的函数,或不一定很慢但被多次调用的方法。
同样的想法亦可用于可视化内存使用情况,其每个节点代表一种特定类型对象,子级是该对象包含或引用的该对象实例的其它类型。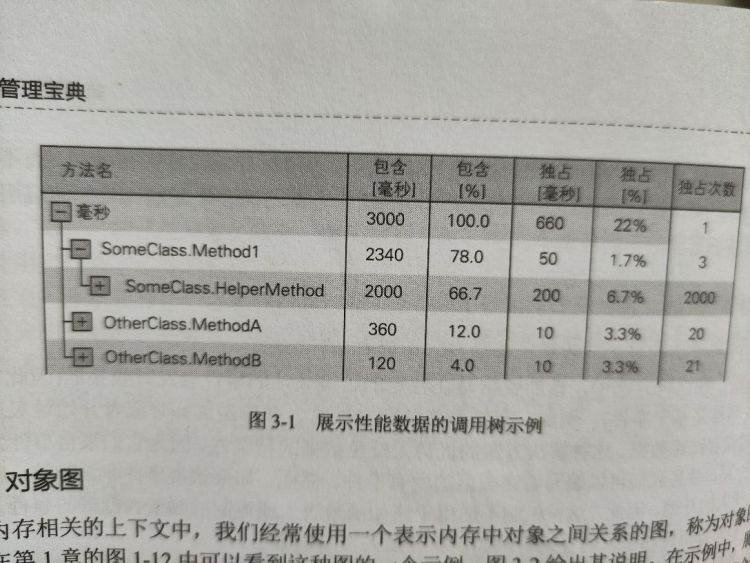
# 对象图
表示内存中对象之间关系的图,称为对象图或引用图。
- 最短根路径:取决于所选对象,从特定对象到某个根的引用的最短路径。
- 依赖关系子图:取决于所选对象,是包含对象本身以及被其直接或间接引用的所有对象的子图。
- 保留子图:取决于所选定对象,指如果删除了给定对象本身则也会被删除的对象的子图。
- (因为依赖关系图很复杂,因此删除对象并不意味着所有依赖于它的对象都被删除了,对它们的引用可能仍然由其它对象保留着)
指示对象大小
- 浅大小:对象本身大小 (其所有字段、包括对其它对象的引用的大小)
- 总大小:对象的浅大小与其直接或间接引用的所有对象的浅大小之和
- 保留大小:保留子图中所有对象的总和,即保留大小是删除给定对象后可以释放的内存量。对象图中不同引用共享的对象越多,保留大小就越小于总大小。(需要对整个对象图进行复杂分析)
# 统计
- 平均值:直观,计算方便,但是其结果没有指向任何特定样本,且容易掩盖数据分发的真实本质。
- 中位数:将样本分为高低两半的值
- 百分位数:低于给定百分比的样本的值
- 直方图:样本分布的图形表示(最好的测量方法)
# 延迟与吞吐量
阿姆达尔定律
- 潜在的延迟加速受程序的串行 (无法并行化) 部分的限制。
- 例如,如果程序的 90% 部分可以并行化,但仍有 10% 的部分必须正常执行,那么最大潜在加速度被限制为最多 10 倍。
# 内存转储、跟踪、实时调试
监视:通过跟踪或采样方式生成诊断信息。
内存转储:在给定时刻保存进程的内存状态。
- 如果没有时间变化背景,有时很难得出具体结论,因此一般进行两个或多个内存转储并相互比较。
- 崩溃转储可作为内存转储一种特殊情况
实时调试:最具侵入性的方法,将调试器直接连接到进程上,然后逐步分析应用程序。
# Windows 环境
# VMMap
查看进程内存使用情况分析,vmmap 检测 .net 托管堆使用的页以及专用于堆栈或加载的二进制文件专用的页。
# 性能计数器
- 性能计数器值的读取完全由我们使用的工具采样的频率来控制。
- 仅当发生特定事件时,才会更新性能计数器数据,之后其值将一直保持不变。
# Windows 事件跟踪
EWT
(诊断功能强大)
# Windows 性能工具包
Windows performance toolkit,WPT 是 Windows 环境中的一组诊断工具,具有搜集和分析 EWT 数据能力。
- Windows performance recorder (WPR,Windows 性能记录器):充当 EWT 的控制器
- Windows performance analyzer (WPA,Windows 性能分析器):充当 EWT 的使用者
# PerfView
# ProcDump、DebugDiag
进行内存转储的工具
前着为命令行,后者为 GUI 工具
# WinDbg
最底层的工具,不管是 net 托管程序还是原生 Windows 应用程序或调试内核本身。
也可以直接附加到托管程序并调试。
默认情况下,windbg 作为原生调试器工作,因此必须使用 windbg 扩展以为其提供 net 相关概念:
- SOS
- SOSEX
- NetExt 和 MEX
由于一次又一次地输入所有命令非常麻烦,可使用命令树窗口简化。
# BenchmarkDotNet
代码性能测量
# 商业工具
visual studio
Scitech .Net Memory Profiler
JetBrain dotMemory
RedGate ANTS Memory Profiler
Intel VTune Amplifier 和 AMD CodeAnalyst Performance Analyzer
- 专门用于基于硬件的底层代码分析,这些工具通常由处理器制造商提供
- 可以从硬件中内置的硬件计数器中获取其有关内部行为的信息:缓存和内存利用率、管道停顿等
- 只有这样的底层工具才能清楚地指出诸如第二章中显示的伪共享之类的问题。
Dynatrace 和 AppDynamics
- 用于监视应用程序性能的上层工具,可持续收集数据
# Linux 环境
略
# 第四章 .NET 基础知识
.NET 整个概念都基于 common language infrastructure (CLI) 的规范,CLI 描述了代码和运行时 环境的概念,并确保无需重新编译的情况在不同计算机运行。
有很多不同 .NET 实现,此处略。
# .NET 内部原理
代码被编译为 CIL (common intermediate language) 然后由 common language runtime (CLR) 执行。CLR 是托管环境的执行核心。
CLR 主要职责:
- JIT 编译器:将 cil 代码转换为机器码。这种执行托管代码方式其实是对原生系统机制的巧妙封装,就像内存管理包含了线程堆栈和堆一样。
- 类型系统:负责管理类型控制和兼容性机制。包括 common type system (CTS) 和 (用于反射机制的) 元数据。
- 异常处理:负责在用户程序和运行时两个层次上进行异常处理。
- 内存管理 (通常指垃圾回收器):运行时中管理内存的组件。
- 执行引擎:负责大部分运行时的职责,包括 jit 编译和异常处理,ecma-335 中被称为虚拟执行系统 (VES),负责加载和运行为 cli 编写的程序。
- 垃圾回收器:负责内存管理、对象分配,回收不再使用的内存区域。
托管代码:包含足够额外信息的代码,这些信息用于使 CLI 为代码执行提供一组核心服务。
- 如给出代码中一个方法地址,CLI 必须能够定位到描述该方法的元数据,还必须能够遍历 stack、处理异常、存储和获取安全信息。
一些误解:
- .NET 并非一般意义上的虚拟机,.NET 运行时不会创建一个隔离环境,也不会模拟任何特定的架构或计算机。其重用了诸如操作系统内存管理之类的内置系统资源,包括 heap、stack、进程和线程等,然后再在这些内置资源之上构建一些附加功能 (自动内存管理等)
- 计算机不会始终运行着一个 .NET 运行时,每个 .NET 程序运行时才被加载和执行
.maxstack:
- 不是 CIL 指令,而是一个元数据描述,其它工具可以使用它验证代码安全性 (防止缓冲区溢出攻击)。其描述了方法执行期间 evaluation stack 中最多可以分配多少字节。
.NET stack machine 的位置概念:
- 方法中局部变量
- 方法参数
- 另一个值的实例字段
- (类、接口或模块的) 静态字段
- 本地内存池
- 暂时放在 evaluation stack 上
JIT 编译器会负责将每个 逻辑位置 映射到特定的计算机架构 (即寄存器操作的机器码)。
# 程序集和应用程序域
为满足安全性、可靠性或版本化需求,应用程序域提供将应用程序代码不同部分隔离到应用程序域中的功能。
- 注:由于为使得 .NET Core 保持精简,应用程序域已移除,不过 CoreCLR 内部依然使用了应用程序域
- (微软建议开放人员使用进程或新式容器实现 .NET Core 程序隔离)
应用程序域分类:
- 共享域:不同应用程序域之间共享代码加载此域。包括 basic class library、system 命名空间中的类型
- 系统域:核心运行时组件加载到此域,负责创建和初始化其它应用程序域。还保存了进程范围内暂存的字符串文本。
- 默认域:用户代码会加载至该域。
- 动态域:通过 AppDomain.CreateDomain 根据需要创建,.NET Core 不提供该功能。
所有共享代码由共享域负责处理,所有用户代码由单个默认域处理。系统域仅存在结构和逻辑,在进程内存中不可见。
# 进程内存区域
每个应用程序域,包括共享域、系统域、默认域及其它所有动态加载的域,都各自有自己的一组堆:
- High Frequency Heap (高频堆):应用程序域基于其内部目的,将频繁访问的数据存储于此。
- CoreCLR 描述:这些堆用于分配应用程序域生命周期内始终存在的数据。为更好管理 page,应将频繁分配的对象分配到高频堆。
- 如详细的方法和字段描述等基元静态数据也存放在这。
- Low Frequency Heap (低频堆):包含了较少使用的类型相关数据,如 EEClass、JIT 编译、反射、类型加载机制所需要的其它数据。
- Stub Heap:文档描述 -- 保存了实现代码访问安全 (CAS)、COM 包装调用和 P/Invoke 的 sub
- Virtual Call Stub:包含用于虚拟 stub 调度 (VSD) 技术所使用的数据结构和代码。
- VSD 技术:使用 stub 用于虚拟方法调用,而非使用传统的虚拟方法表。
- High Frequency Heap、Low Frequency Heap、Stub Heap 和各种 Virtual Call Stub 都统称为 Loader Heap 类型,因为它们存储的都是类型系统所需的各种数据 (因此加载任何一个类型时都需要它们)
- 即虽然有 Loader Heap 这个术语,但内存其实不存在一个 Loader Heap,而是代表上述内存区域统称
- 注:加载至 Loader Heap 区域的类型的生命周期跟随应用程序域。
# 类型系统
Common Type System (通用类型系统)
.NET 中每种类型都由一个称为 MethodTable 的数据结构描述,其中包含类型的大量信息,最重要的有:
- GCInfo:用于垃圾回收器用途的数据结构
- 标志:描述各种类型的属性
- 基本实例大小:每个对象的大小
- EEClass 引用:存储通常仅用于类型加载、JIT 编译或反射的『冷』数据,包括所有方法、字段和接口的描述信息。
- 调用所有方法 (包括继承自基类的方法) 所需要的描述信息。
- 静态字段有关的数据:包括与基元静态字段有关的数据。
只要有需要,运行时将通过访问 MethodTable 的地址 (表示为 TypeHandle) 获取被加载的类型信息。
# 类型的分类
- 值类型:这种类型的实例直接包含其所有数据 (值类型的值是自包含的)
- 引用类型:这种类型的实例包含对其数据的引用 (引用类型所描述的值指示其它值的位置)
# 生存期
- 值类型实例包含的数据,其生存期与实例本身一样长
- 引用类型的值描述了其它值的位置,那些值的生存期并不取决于引用类型值本身
# 可共享性
- 值类型的值不可共享,如果想在其它地方使用,默认只会按照字节复制一份出来。复制值不影响原始值。
- 引用类型的值可被共享,在传递之后会多出一个指向同一个位置的引用类型实例。
# 相等性
- 值类型不存在相等性,当且仅当它们值的二进制序列一样时才认为完全相同
- 引用类型当且仅当它们指示的位置一样就是完全相同的
# 类型的存储
存储在堆栈,还是存储在堆?这是实现细节上的决策。通常值类型和引用类型存储位置的说法,并不准确,因为他们存在包含关系。
注:CLI 标准中并未指定关于存储位置的任何实现细节决策。
# 值类型
ECMA335:类似整数或浮点数,值类型使用了一种简单的将数据直接按位存储模式。每个值都有一个类型,该类型描述了它使用的存储空间以及它的表现方法中各个位 (bit) 的含义,也描述了对该表现方式进行的操作。在编程语言中,值通常用于表现简单类型和非对象。
通用语言规范 (CLS) 定义了两种值类型:
- 结构:包括许多内置整型类型 (char/byte/integer)、浮点类型和布尔类型
- 枚举:基本是整型类型的扩展,由一组命名常量构成。从内存管理的角度看就是整型类型(内部本质上是结构)
# 值类型的存储
『堆栈是一种轻量级机制,只需要创建一个大小合适的 activation frame 并在不再需要时将其关闭,就可以在堆栈上 分配 和 回收 对象』
但堆栈的生存期和值本身需要的生存期不匹配,生存期和值共享这两个因素,决定我们可以使用何种机制存储值类型数据。
值类型可能出现位置:
- 方法中局部变量:具有非常严格和定义良好的生存期,其长度和方法的调用时长相同。
- CLI 指出:引用局部变量或参数变量的托管指针,有可能出现引用失效的问题,因为它的行为无法验证。
- 方法的参数:可以完全被视作局部变量。
- 引用类型的实例字段:其生存期取决于父值的生存期。将于引用类型一并被分配于堆。
- 另一个值类型的实例字段:跟随父值。
- (类 / 接口 / 模块中的) 静态字段:静态字段的生存期和定义此字段的类型等长,因此肯定不能使用堆栈保存。
- 局部内存池:生存周期与方法生存期严格等长,堆栈
- evaluation stack 上临时值:处于性能考虑,JIT 显然会尽量使用 CPU 寄存器和堆栈。
# 结构
- 分配于堆上而非栈上:可以从实现细节上受益,例如避免 GC 管理它们所带来的开销。
- 较小:结构只存储其数据而无需存储任何额外的元数据,因此所需内存更小。
- 提供了更佳的数据局部性:由于结构更小,因此可以更密集地在集合中打包数据。
- 访问速度更快:直接包含数据,因此访问时无需进行额外的解引用 (dereferencing) 操作。
- 天然具有传值语义
# 结构概述

上图内存区域可能位于堆栈、堆,甚至 CPU 寄存器。
不过当前 CLR 实现不允许直接在托管堆上使用上述布局,托管堆中的对象必须是自描述的引用类型。因此当需要在堆中存储结构时,将执行装箱 (boxing)。
- 当结构被装箱,就将很难再获得结构的种种优点。结构的真正能力只在未被装箱的情况才能得以体现。
优化内存和性能的核心规则之一是:避免分配,结构即是帮助我们应用这条规则的利器。
此外,由于结构的限制,比如不带继承功能,可以让编译器可以对其使用方式进行大量预判。
# 结构的存储
- ldloca.s 0:将第一个局部变量的地址推入 evaluation stack
- initobj:从 evaluation stack 取出并移除地址,将其指向内存初始化为指定类型初始值
- ldarg.0:将方法的第一个参数 (实例方法为 this) 推入 evaluation stack(后续参数依此类推)
- ldloc.0:将第一个局部变量的值推入 evaluation stack
- call:调用方法,结果放入 evaluation stack
- ret:从方法返回至调用者
- newobj:堆分配
对于小型结构数据,JIT 可以仅使用 CPU 寄存器从而完全避免使用堆栈以极大优化性能 (生成的机器码中彻底没有了结构的概念)。
还可以对 (大型) 结构体使用传引用优化复制效率。
结构是高效的数据容器,其简洁性提供了极大的代码优化潜力,『局部结构类型变量被分配在堆栈上』确实不假,但实际情况可能比这更好,局部变量可以被优化成完全由 CPU 寄存器处理而无需用到堆栈,从而使按值传递也不过需要对 CPU 寄存器进行一些操作而已。
注 1:release 和 debug 模式编译后代码有很大差异。
注 2:影响 JIT 优化与否的大小大概是 24 字节,可以安全假设 JIT 将对不超过 16 字节的结构进行优化。(注意测试代码是 64 位 RyuJIT 编译器)
注 3:在一个结构体方法中可以将新值赋给 this 字段,是由于结构体直接存储数据,可看作再次初始化。
# 引用类型
通用规范中定义了两种主要的引用类型:
- 对象类型: ECMA335 所述,对象是 自描述值的引用类型,类型显示存储于其表现形式中。包括类和委托。
- 指针类型:一个指向某个内存位置的特定于当前计算机的纯地址。指针分为托管指针和非托管指针两种。
概念区分:
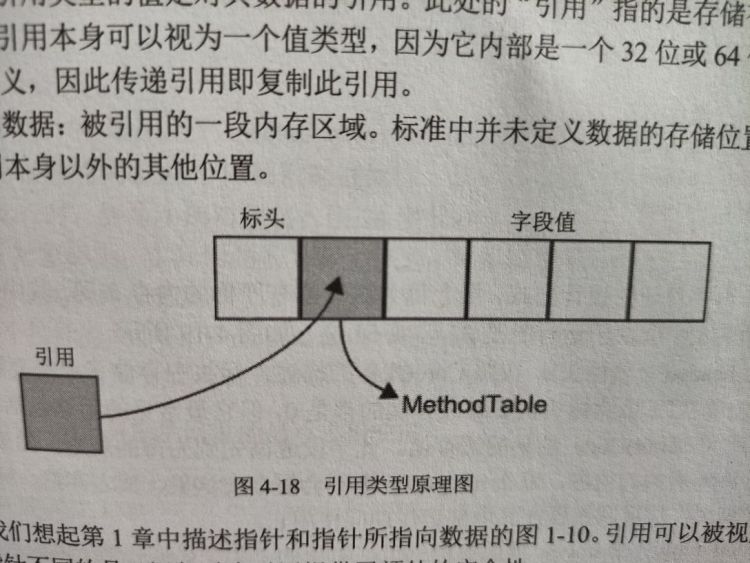
- 一个引用类型的值是对其数据的引用,引用本身可被视为一个值类型,内部是个 32 位或 64 位地址,引用具有传值语义。
- 引用类型的数据:被引用的一段内存区域,标准中并未定义数据的存储位置,反正它肯定存储在引用本身以外的其它位置。
引用可以被视为指针的一种,但与普通指针不同的是运行时为引用提供了额外的安全性。
注:存在一种逃逸分析的技术,也许可以让类分配于堆栈,不过 .NET 目前不支持。
# 类
由于 .NET 内存管理的设计方式,堆上每个对象都有严格的内存布局:
- object header:存储了需要附加到对象上的所有附加信息,大多数时候都是 0。
- 常见的用途有:此对象上的 lock 信息或 GetHashCode 结果缓存值(遵循先到先得规则)
- method table reference:即 MethodTable 引用,指向类型描述数据结构中的一个相应条目 (位于 high frequency heap)。这里也是对象相互引用时的引用点。
- 数据占位符 (若类型没有字段):当前垃圾回收器要求每个对象都至少有一个指针大小的字段。
- 该字段不必专门用于垃圾回收,而是可以其它各种用途重用 (如用作存储对象第一个字段 - 如果有的话)
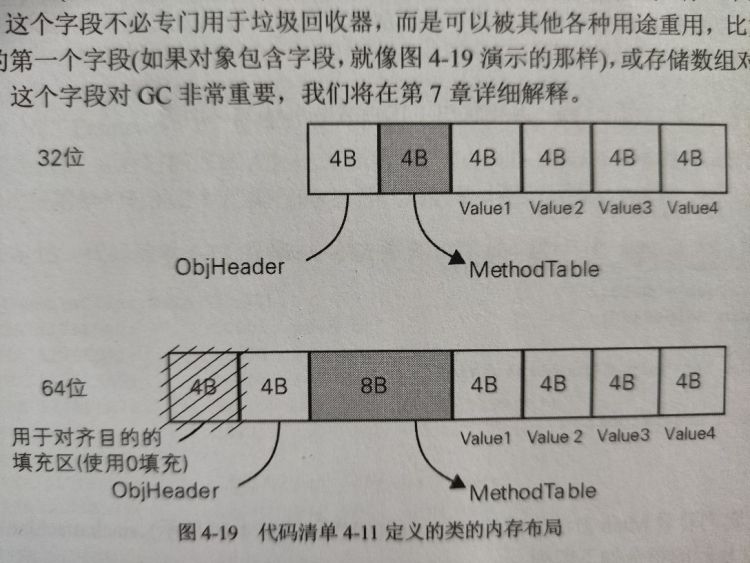
堆上每个对象都至少包含上述三个字段。
32 位 最小堆对象为 12 字节:
- 4 字节用于对象标头
- 4 字节 (一个指针大小) 用于 method table reference
- 4 字节 (一个指针大小) 用于内部数据占位符
64 位 最小堆对象位 24 字节:
- 8 字节用于对象标头:实际只用到 4 个字节,另外以 0 填充的 4 字节仅用于对齐目的(64 位架构基于 8 字节对齐)
- 8 字节 (一个指针大小) 用于 method table reference
- 8 字节 (一个指针大小) 用于内部数据占位符
一个包含 1 字节数据的分配于堆栈上的结构仅占用 1 字节空间 (内存对齐可能有额外开销),而一个包含 1 字节数据的分配于堆上的类将在 64 位运行时占用 24 字节空间,两者内存开销相差明显。
另外,类生成的最终汇编代码也比结构更复杂,在测试代码中,类的性能与结构之间相差超过 4 倍。
# 字符串
字符串不可变性仅体现在 Basic Class Library 未提供任何修改字符串的 API,但在运行时并没有这个限制。
- 它只是一段连续的、以某种方式表示字符的字节区块,完全可以使用 unsafe 模式使用指针修改 —— 当然这种做法是不受支持的。
string.format、string.join 等常见辅助函数内部已经使用了 stringbuilder,为进一步优化甚至甚至进一步封装了 StringBuilderCache
- StringBuilderCache 内部存储了一个 thread static stringbuilder,每个线程上都会创建一个专门的实例,因此是线程安全的。
字符串不可变优缺点:
- 优点
- 安全性
- 并发性
- 缺点
- 修改操作将导致额外字符串实例
# 字符串暂存
.NET 运行时内部有一个名为字符串暂存 (string interning) 的机制,此机制默认仅适用于字符串字面量 (string literal)。
- .NET 内部也提供了手动暂存的 API
暂存的字符串由 StringLiteralMap 和 LargeHeapHandleTable 注册和管理,这几个数据结构生成周期与应用程序一样长。
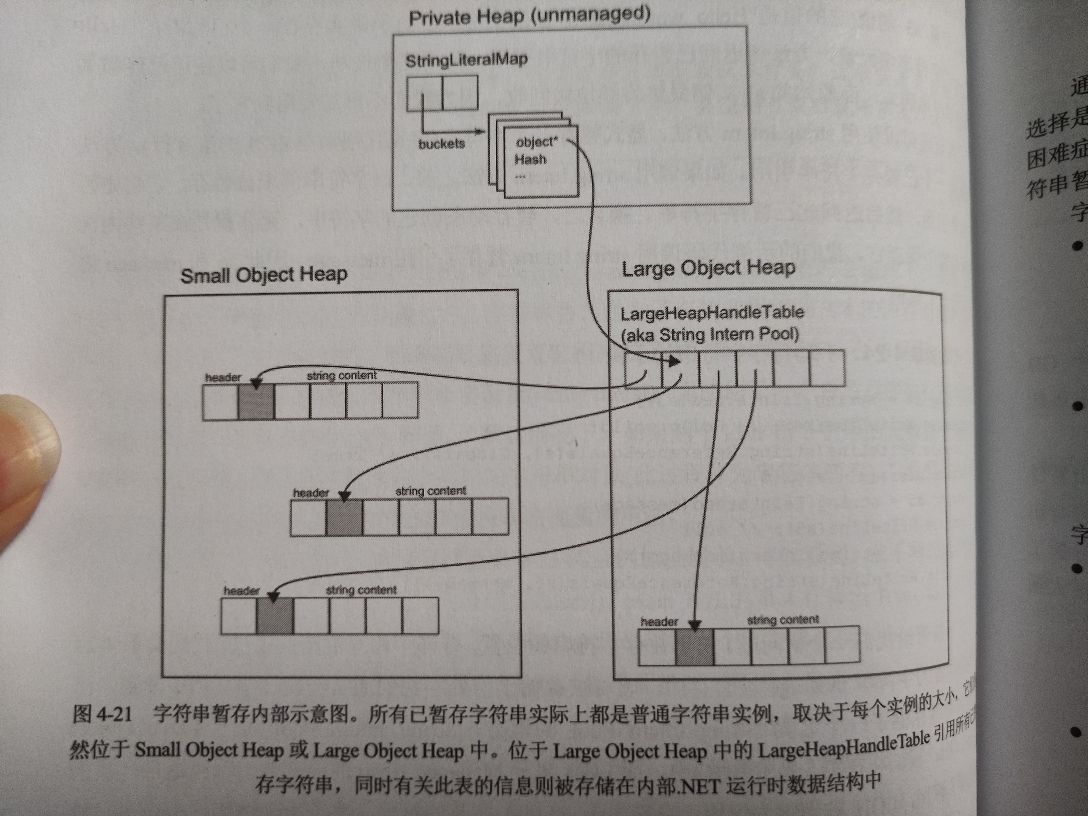
字符串暂存优缺点
- 优点
- 消除重复字符串
- 提供相等比较性能
- 缺点
- 永续性:暂存字符串将永远保持可达状态
- 创建临时字符串:只能暂存已创建的字符串,因此即使仅用于检查是否存在某个已暂存字符串,也会有一个留存极短时间的未暂存字符串。
结论:字符串暂存仅在大量重复字符串需要长时间保留于内存下才有意义。(该场景似乎并不常见)
# 装箱与拆箱
是一个效率较低的操作,应尽量避免。例如避免在需要对象 (引用类型) 的地方使用值类型。
- 作为一个通用规则:尽量避免在调用以 object 类型为参数的方法。
注:以接口类型使用值类型实例 (若值类型实现了该接口),由于接口是引用类型,因此同样会导致装箱。(可以考虑利用泛型优化,泛型方法将被编译为特定具体类型的方法)
foreach 遍历值类型列表,会导致隐式装箱。
- 为何 list<> 这类常见集合类型采用结构实现枚举器?
- 绝大部分场景中,枚举器都被当做一个局部变量,值类型可以快速低廉地在堆栈上分配 (好处超过装箱可能带来的问题)
与装箱对应是拆箱,不过拆箱不会导致太大内存开销。
# 按引用传递
我们可以按引用传递任何值,无论它是值类型实例还是引用类型实例。
# 类型数据局部性
结构的数据构造内存使用效率更好。
且结构体数组才是内存连续,而引用类型数组只包含连续的引用,实际值分散于整个托管堆。
- 类实例数组有额外一次解引用,并且无法在内存中连续排列,因此类实例数组具有更差的数据局部性,加载类数组必须使用更多的 cache line,导致其性能会相差更大。
# 静态数据
静态数据可以被视作程序中的一种全局变量。
- C# 仅支持一种静态数据类型:静态字段
# 静态字段
静态字段的值被该类型的所有实例所共享,通过使用类型名称,在任何可以访问该类型的地方都可以访问该类型上定义的静态字段。
- 静态数据具有应用程序域作用域 (每个应用程序域单独一份实例)
- 定义在一个程序集的类型上的静态数据将一直存活到应用程序域被卸载 (使其引用的静态数据和对象也将保持可达)。
实现细节
- 静态基元数据 (如数字) 存储于相应应用程序域的一个 HighFrequencyHeap 中
- 静态引用类型实例存储于常规 GC Heap 中,与普通对象区别在于额外被一个内部 static table 引用
- 静态用户自定义值类型实例 (结构) 将以装箱形式存储于常规 GC Heap 中
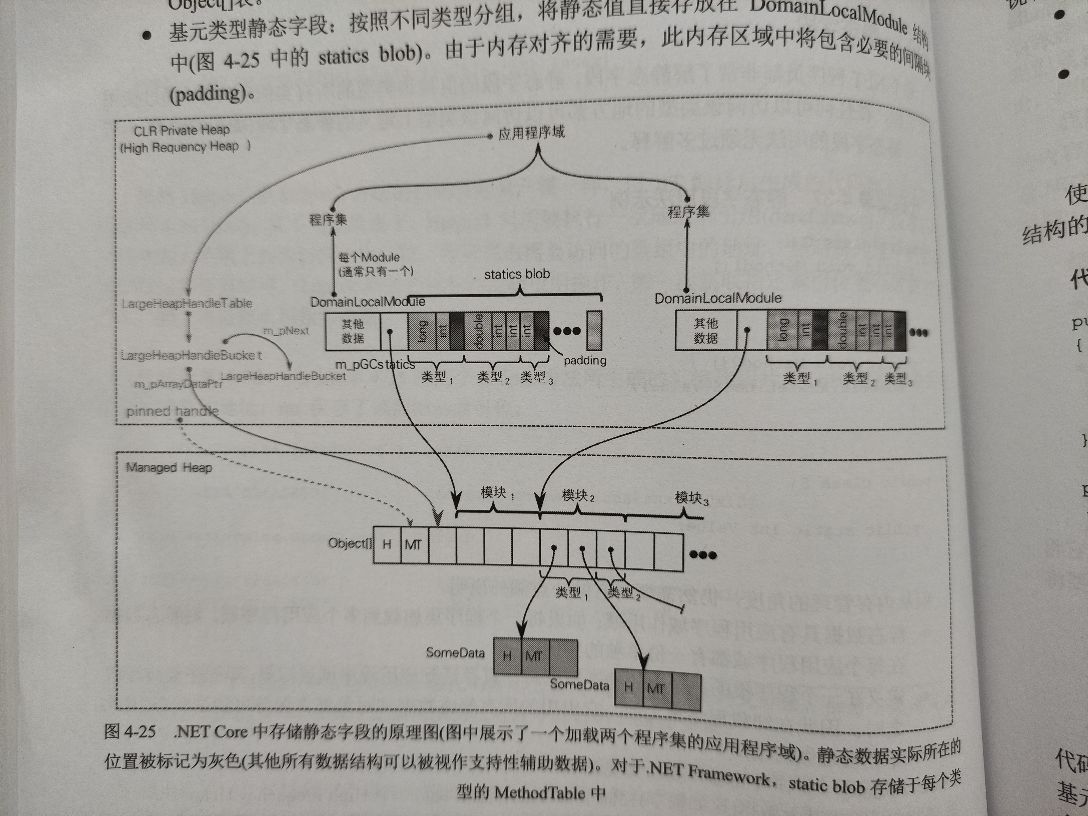
访问
- 对于基元类型静态字段,已知维护此字段的 DomainLocalModule 地址和要访问的字段在 statics blob 中的偏移量,计算后可得静态数据的绝对地址
- 对于引用类型静态字段 (包括结构类型,其以装箱形式分配在堆上),已知对应 object [] 数组的地址和访问字段偏移量,计算出静态字段的绝对地址,获得指向托管堆真正实例数据的引用。
访问基元静态字段的速度非常快,它唯一做的操作就是从适当的 statics blob 区域读取一个指定值。
访问类型 / 结构静态字段数据需要执行解引用操作,并随之带来额外开销。
