
# 第二章 底层内存管理
# 硬件
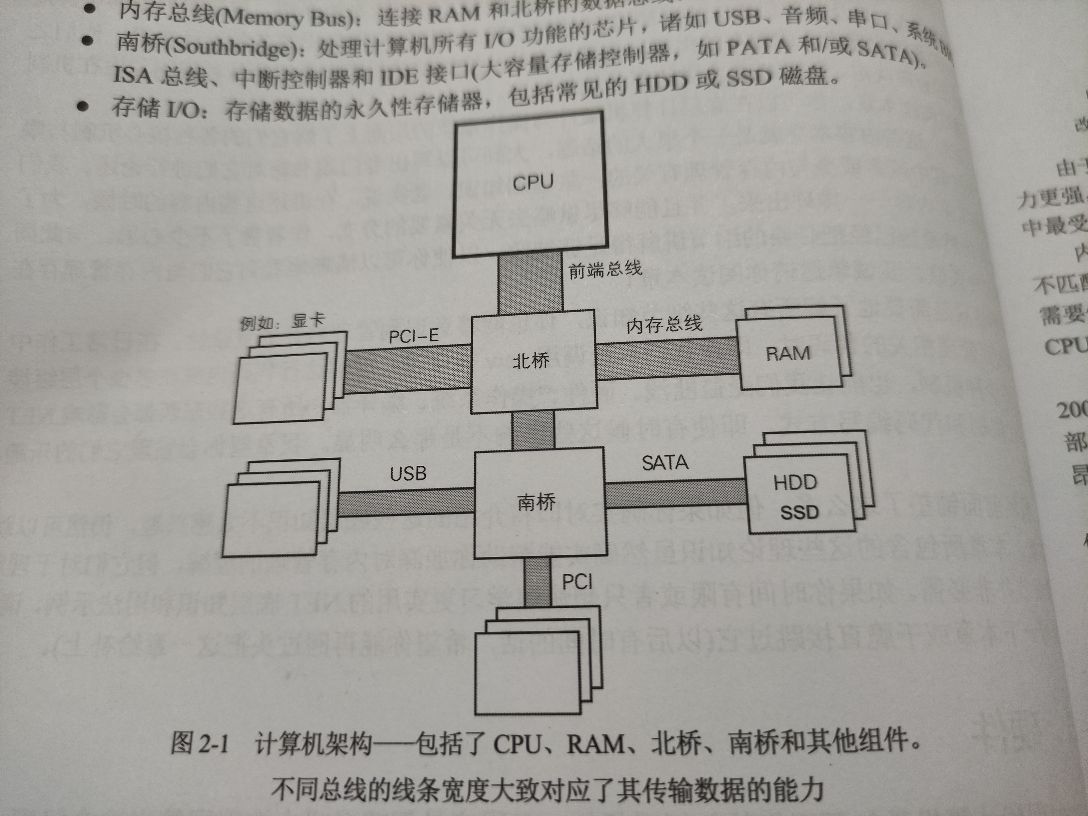
- 处理器 (CPU):计算机的主单元,负责执行指令。包含算数逻辑单元 (ALU)、浮点单元 (FPU)、寄存器和指令来执行流水线 (负责高效执行被切分成一组更精简指令集的操作指令,并在可能的时候并行执行它们)
- 前端总线 (front side bus,fsb):连接 CPU 和北桥的数据总线
- 北桥 (northbridge):主要包含内存控制单元,负责控制内存和 CPU 之间的数据通信
- RAM (随机存取存储器):也叫易失性存储器
- 内存总线 (memory bus):连接 RAM 和北桥的数据总线
- 南桥 (southbridge):处理计算机所有 I/O 功能的芯片
- 存储 I/O:存储数据的永久性存储器
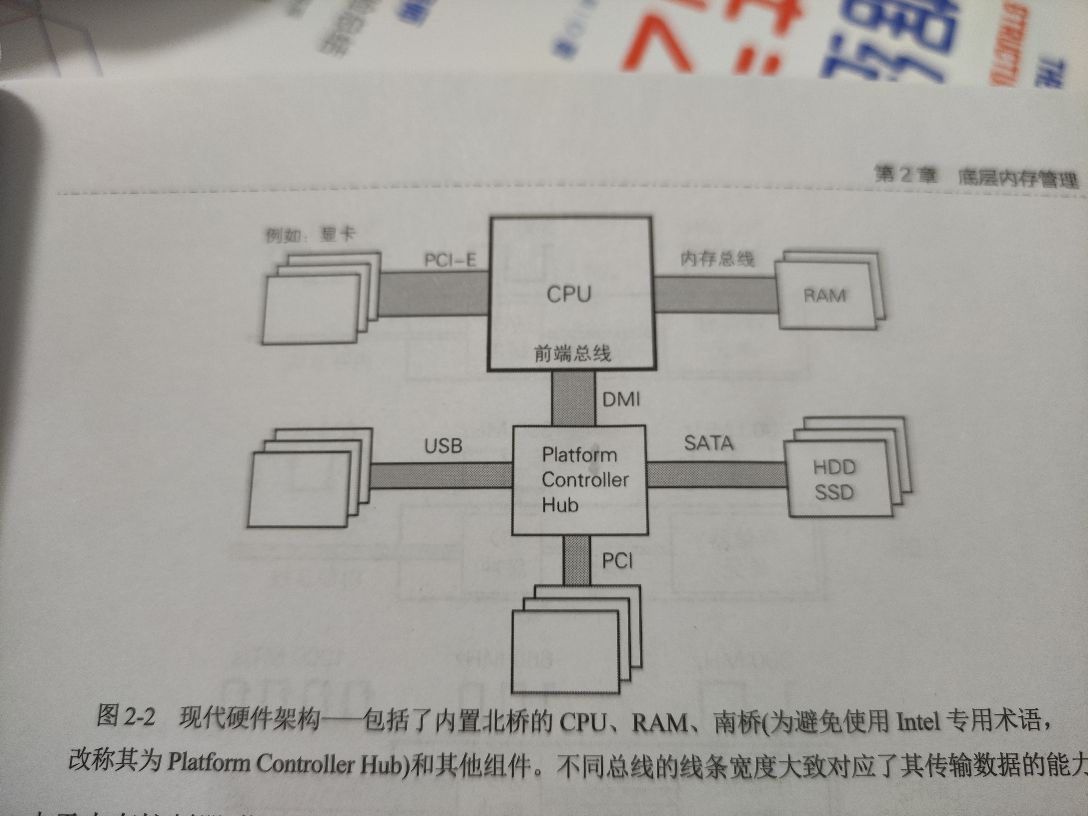
注:现代计算机架构北桥芯片被内至于 cpu 中,由于内存控制器与 cpu 执行单元距离更近,降低了整体通信延迟
内存管理背后的主要问题是当今 cpu 的强大处理能力与内存和大容量存储子系统之间的不匹配
- 当处理器需要访问内存时,都会导致额外的延迟
- 当 cpu 需要停下来等待对内存数据的访问 (无论写入或读取) 完成时,称之为停顿。停顿越多,cpu 利用率就越低
目前主流内存的内部时钟频率非常低,依靠多种技巧提升频率。内存模块由内部存储单元和附加缓冲器组成,后者用于协助突破内部低时钟频率的限制。
- 单个时钟周期内,从内部存储器单元发送两次数据:准确是是在时钟信号的下降和上升周期分别发送一次数据。例如:双倍数据传输率 (double data rate,ddr)
- 在单个时钟周期内,使用内部缓冲一次进行多次读取
即使 DDR 内存已经应用了各种优化手段,但 CPU 的速度仍然比内存快。为克服这个问题,在不同层面都引入了一个相似方法:将一部分数据放到性能更好 (同时更昂贵) 的存储器中,即称为缓存。
# 内存
目前存在两种主要内存类型:
- 静态随机存取存储器 (static random access memory,SRAM):具备极高的访问速度但工艺复杂,占用面积大,每个存储单元由 6 个晶体管组成 (用于存储单个比特)。只要保持通电数据就可以一直保存,无需刷新。主要用于 cpu 缓存。
- 动态随机存取存储器 (dynamic random access memory,DRAM):存储单元的结构简单很多 (比 SRAM 小很多),由单个晶体管和电容器组成。
- 由于电容会漏电,一个存储单元需要不断地刷新其自身保存的数据 (这将耗时宝贵的几豪秒并拖慢读取内存速度)。
- 从电容器读取的信号还需要被放大,导致整个过程更为复杂
- 由于电容器本身存在延迟,数据的读取和写入也需要额外耗时,且耗时时长并非线性 (需要等待一段时间以确保数据的正确读取和成功写入)
芯片面积和工艺决定芯片价格,同容量的 SRAM 价格更贵
我们计算机安装的内存,即 DRAM 为了减少成本,是进行行列地址复用的 (芯片引脚数不够),通常寻址结构如下:
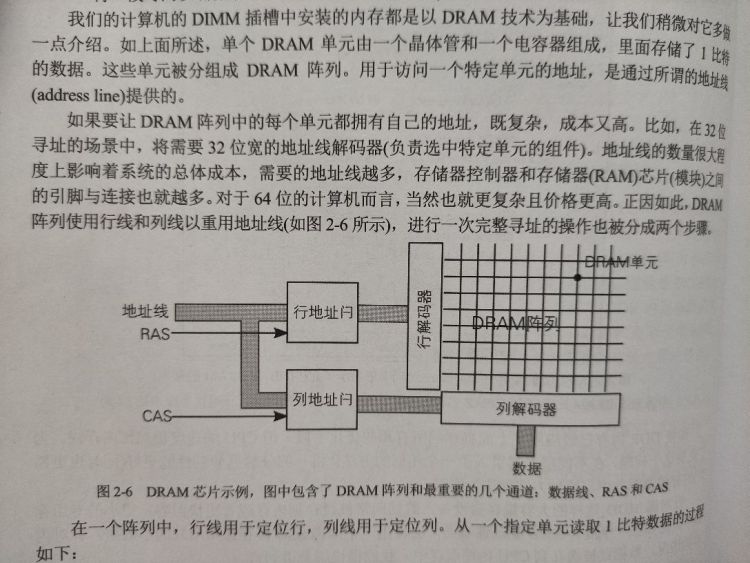
从一个指定单元读取 1 比特数据过程:
- 将行号放在地址线上
- 行地址选通 (row address strobe,RAS) 信号在行地址线上触发对行地址的解码
- 将列号放在地址线上
- 列地址选通 (column address strobe,CAS) 信号在列地址线上触发对列地址的解码
- 读取 1 比特数据 (定位到特定的 DRAM 单元)
上述每个步骤切换时长
对内存性能有巨大影响,比如内存延时标识如 DDR3-9-9-9-24:
- tCL (CAS):列地址选通和起始应答 (获得数据) 之间的时长
- tRCD (RAS 到 CAS 的延迟):之间可能导致的最短延迟时长
- tRP (行预冲):访问一行之前,对它进行预冲 (precharge) 所花费的时长。使用一行之前必须先对它进行预冲。
- tRAS (行激活延迟):激活一行以访问其信息的最短时长。这个时长通常至少是上面 3 个时长之和。
若已经设置了需要访问的行和列,其所在位置数据几乎可以被即时读取。
- 如果需要更改读取列,将花费 tCL 个时钟周期。
- 如果想要更改读取行,情况会更糟:必须先预冲 (tRP 个周期),然后再经历 RAS 和 CAS 所导致的延迟 (tCL 和 tRCD 个周期)
DRAM 存储器架构和它的延迟时长对于内存管理的影响:
- 更改访问的行是耗时最长的操作,它包含了 RAS 信号、预冲等带来的延迟
- 因此内存循序访问模式远快于非循序访问模式
注:尽量避免对内存的非循序访问。
# CPU
cpu 运行机制中的一个核心角色是寄存器,因为当前所有计算机都是以寄存器机器的形式实现的。
- cpu 操作数据时,访问寄存器是即时可得的,整个操作可以在一个处理器周期内完成,不存在任何形式延迟
- 寄存器是最靠近 cpu 的数据存储位置(当然,寄存器存储的是当前指令所需要的数据)
# CPU 缓存
采用 SRAM 芯片,容量较小,但由于采用了高成本的方案,其速度可以与 CPU 匹敌或仅慢上一两个数量级
注:从 ISA (instruction set architecture)
的角度看,不管是程序员或操作系统,都不需要对它的运作进行任何管理。理想情况下应当仅是 cpu 的责任。
# 缓存命中与未命中
当处理器执行的指令需要访问内存 (不管是写操作还是读操作),它首先查看缓存,检查需要的数据是否已经位于缓存中。
- 如果存在,则可以以极快速度获取数据,即为缓存命中
- 若不存在,即为缓存未命中,处理器就需要从内存中读取数据,再将数据放到缓存
# 数据的局部性 (data locality)
缓存的理念基于一个重要概念:数据局部性
- 时间局部性:如果访问了一些内存区域,那么很可能很快还需要重复访问
- 空间局部性:如果访问了一些内存区域,那么临近区域很可能也会访问到
缓存是一把双刃剑,如果我们写出的程序破坏了数据局部性,缓存反而会带来不必要的负担。
# 缓存的实现
缓存行 (cache line):在内存与缓存之间传输数据时,以此数据块进行。其具有固定大小,在当今计算机中,大小都是 64 字节。
注意:不能从内存中读出或写入小于 cache line 大小 (64 字节) 的数据。即使从内存读取 1 比特也会一次性读取出整个 64 字节大小的一块数据。
- 设计目的是为了更好地遵循 DRAM 访问 (预冲、RAS 延迟)
由于对 DRAM 访问是以 64 位 (8 字节) 为单位,因此填充一个 cache line 需要与内存进行 8 次数据传输。
- 由于 8 次传输需要花费相当多 cpu 周期时间,因此发展出一些优化,如:关键词优先和提前重启动 (critical word first & early restart),首先读取最需要的字并执行,cache line 剩余部分异步填充
注:缓存修改分为直写和回写策略
另外注意: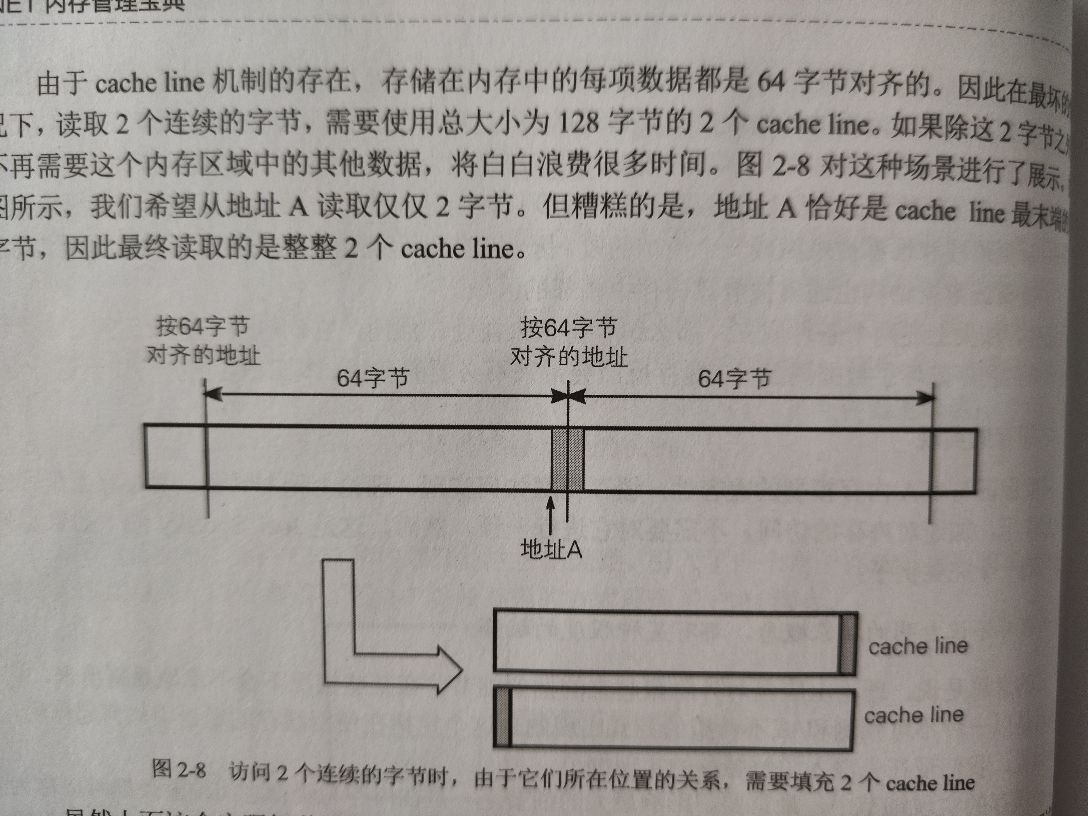
如对二维数组进行逐行索引和逐列索引的差异
# 数据对齐
对齐的意思是指数据的起始地址是给定对齐方式 (指定为 N 字节) 的整数倍。一个数据结构的对齐方式取决于它的字段的对齐方式。
未对齐数据访问速度相比已对齐数据慢很多,对于 CLR 数据结构,数据布局由运行时自身进行管理。
# 非时态访问 (non-temporal access)
在大多数常见 cpu 中,不能绕过缓存去直接访问内存,cpu 对 DRAM 的所有内存读取和写入操作,都存储于缓存中。
假设想要初始化一个大数组,但并非立即使用,正常情况下:
- 数组将分块以 cache line 为单位依次被写入
- 每次写入操作都包含 3 个步骤:将 cache line 读入缓存;修改缓存内容;将 cache line 写回主内存
- 仅仅为了把数据写回主内存就需要填充 cache line,且会抢占本来可以用于其它程序的缓存
可以通过一种称为非时态访问的汇编指令避免上述所说的缓存占用,指令包括:MOVNTI/MOVNTQ/MOVNTDQ 等,可以让程序员向内存写入数据时避免把数据加载到缓存中。
注:C# 可以通过 P/Invokes 调用 _mm_stream_si128
# 预取
数据局部性是让缓存自动起作用的特性 (只要程序员不破坏数据局部性就行)
不过还有另一种提高缓存利用率的机制:将短期之内可能用到的数据提前填充到缓存,因此称之为预取。
- 硬件驱动:当 cpu 注意到一些缓存未命中的情况存在某些特定模式时触发。
- 软件驱动:在代码中通过 C/C++ 的 _mm_prefetch () 函数调用 PREFETCH0 指令显式触发
与其它所有缓存机制类似,预取也是一把双刃剑。
如果在内存中不以正确的方法排列数据,预取和基于 cache line 访问内存等特性对性能显然起不到多大正面作用。
内存不仅是一块平坦的空间,如果我们总是从这里读取 1 字节,从那里读取 1 字节,就必然会承受相应的代价。
# 分层缓存
对于 cpu 架构,一方面我们需要高性能,另一方面又希望成本可控。因此都引入了一种更复杂的分层缓存设计。
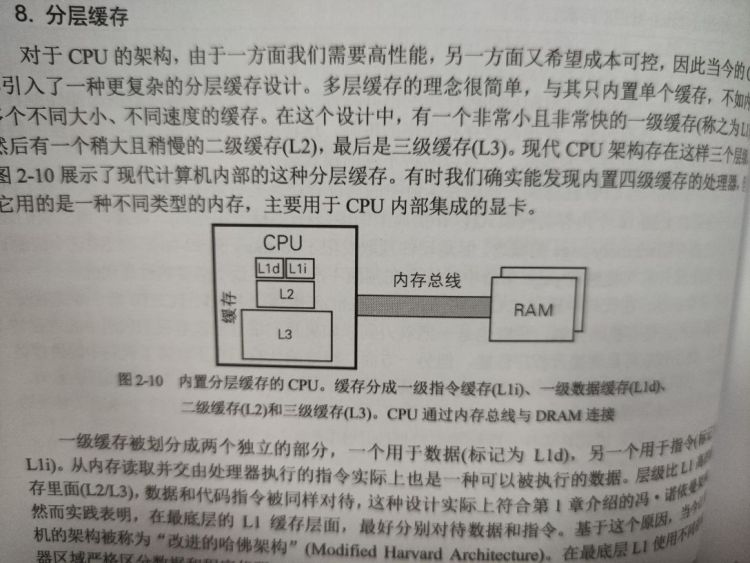
一级缓存:被分为两个独立部分,一个用于数据,一个用于指令
二级、三级缓存:指令和数据被同等对待
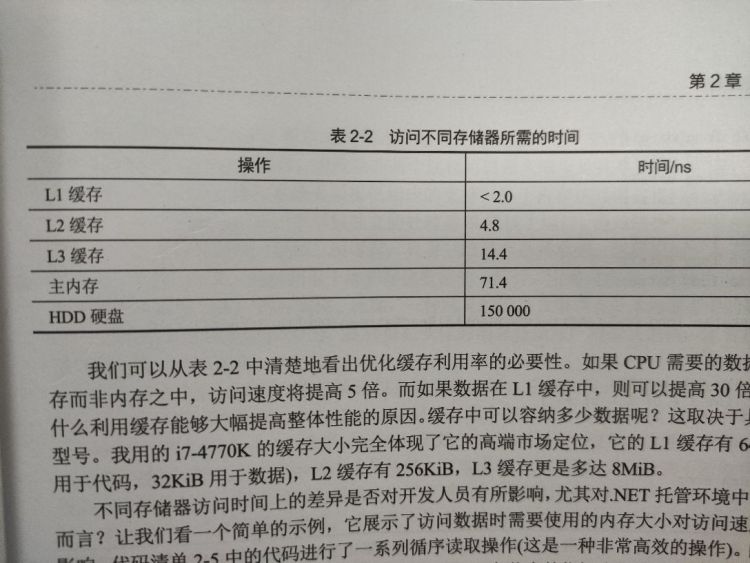
# 多核分层缓存
cpu 每个核心都有独占的一级、二级缓存,并共享同一个三级缓存。
每个核都有自己的一级和二级缓存,只有三级缓存共享,这种架构导致引入了一个复杂概念:缓存一致性
- 该机制用于维护数据一致性,通过缓存一致性协议 (一种将数据变化告知各个核的方法) 实现
- 存在许多高级的缓存一致性协议以及扩展,如流行的 MESI(modified、exclusive、shared、invalid)
缓存一致性协议可以导致产生很大的内存通信流量,从而严重影响程序总体性能。
- 因此编写代码应尽量避免从不同的核去访问相同的 cache line 下内存地址,最好完全避免跨线程通信
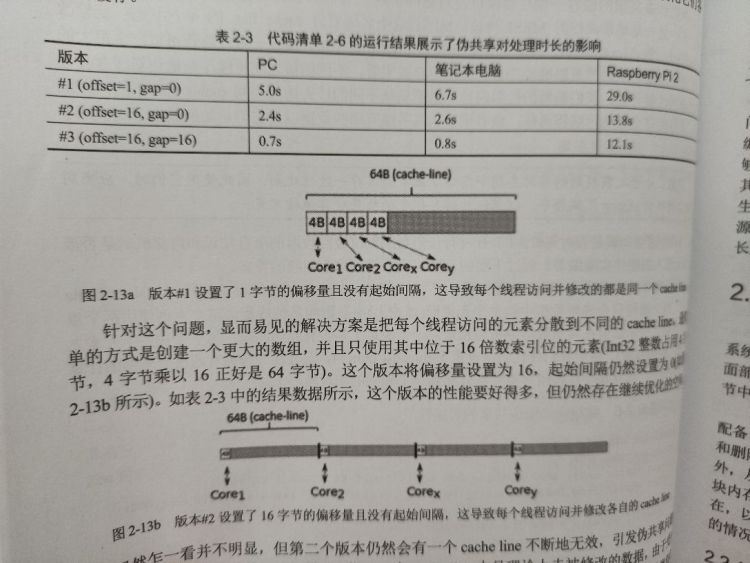
伪共享:位于一个 cache line 中且理论上未被修改的数据,由于受到其它线程的影响而导致其不断变为无效状态。
# 操作系统
# 虚拟内存
每个程序直接管理真实物理地址非常麻烦和危险 (如避免干扰其它程序),为此引入了该概念:
- 将内存管理逻辑从程序转移到操作系统,并向程序提供虚拟地址空间。
- 这意味着每个进程都认为它上系统中运行着的唯一一个进程,所有内存都为自己所用。
- 而且由于地址空间是虚拟的,因此甚至可以大过实际物理内存大小 (扩展内存)。
内存管理程序两个主要职责:
- 将虚拟地址空间映射到物理内存:32 位、64 位计算机分别使用对应位长的虚拟地址。(目前 64 位通常使用低 48 位,可以支持最大 128TB 内存寻址)
- 将一些此时不需要的内存区域从 DRAM 转移到硬盘 (page file、swap file)
虚拟内存在 cpu 中通过内存管理单元 (memory management unit,MMU) 执行并与操作系统协同工作。
每个进程都有一个由操作系统维护的 page 目录,作用是将一个虚拟地址映射到物理地址:page 目录中的一个条目指向一个 page 的物理起始地址等信息,典型的 page 大小是 4KB。
虚拟地址向物理地址转换需要遍历一个 tree 结构完成,会有开销,因此引入了将转换结果缓存的组件:translation look-aside buffers (TLB)
- 类似键值对 map 结构,未命中才会执行一次代价高昂的 full-page 目录遍历
# Large Page
虚拟地址转换成本可能较高,可以使用较大的 page,由于同一个 page 可以容纳许多地址,TLB 缓存转换结果后,地址转换需求就变少了(但大 page 同样会浪费资源)
# 通用内存布局
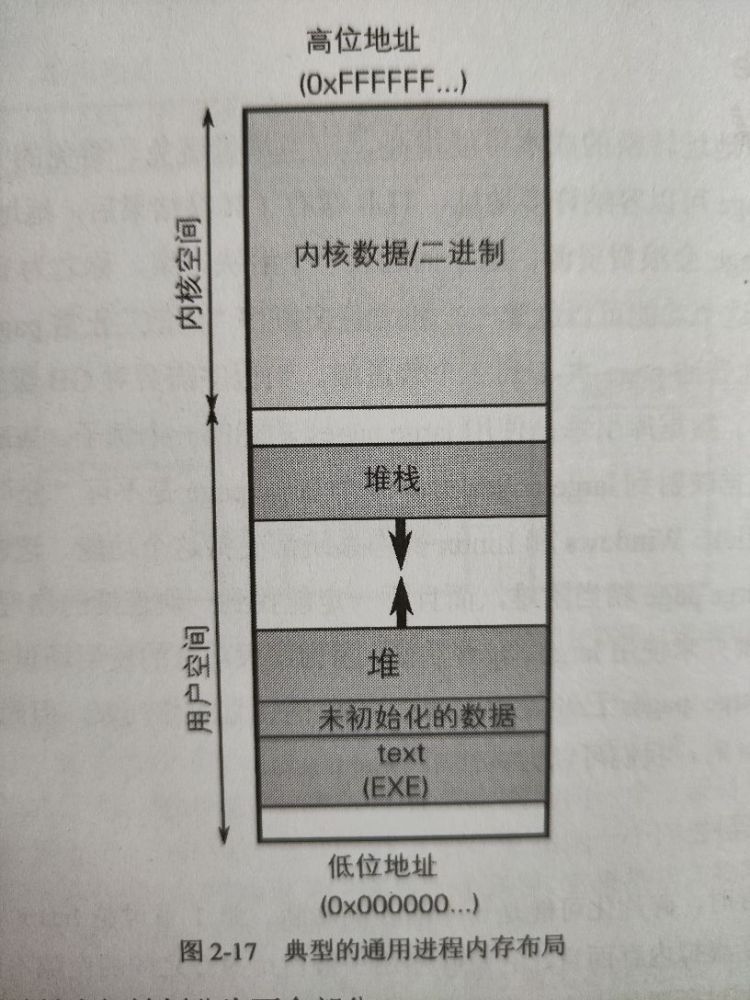
虚拟地址空间被划分为两个部分:
- 内核空间:高位地址空间被操作系统占用
- 用户空间:低位地址空间被分配给进程
注:看起来 stack 和 heap 最终似乎有可能碰到一起,但因为两者大小都是受限的,因此永远不会发生。
内存段:
- 数据段:包含已初始化和未初始化的全局变量和静态变量
- text 段:包含应用程序二进制和字符串文本 (根据定义,只包含只读数据)
# Windows 内存管理
当 Windows 为一个进程保留内存区域时,将遵循如下限制:
- 内存区域的起始地址和大小,都必须是系统 page 大小(通常 4KB)和分配粒度(通常 64KB)的整数倍,否则若试图分配小于粒度的内存空间,剩余部分将被标记为不可用。
- 因此为避免浪费,应使用合适的对齐方式和大小使用内存块
既然 page 大小是 4KB,为何分配粒度是 64KB?
- 历史原因导致
# Windows 内存布局
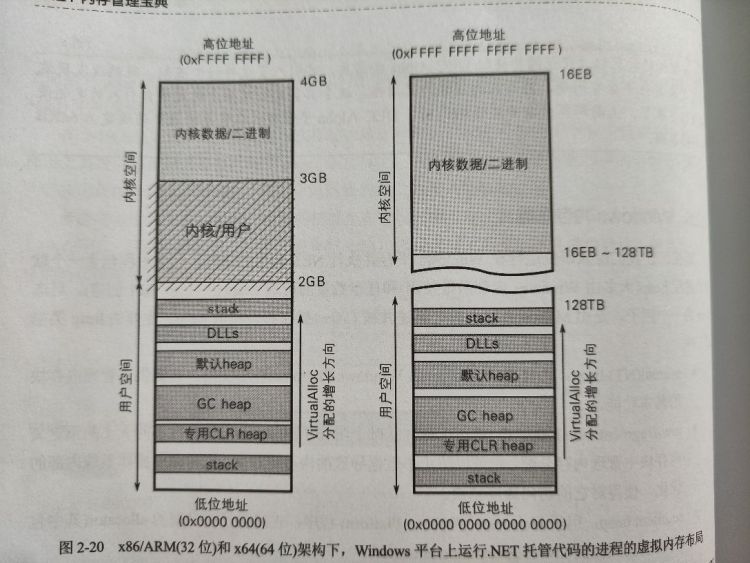
.Net 中默认栈大小:
- 典型 32 位:1MB
- 典型 64 位:4MB
注 1:Windows 上初始线程栈大小取自可执行文件标头,因此也可通过修改 .Net 可执行二进制文件标头修改
注 2:出于安全考虑,系统引入了一种地址空间布局随机化 (address space layout randomization,ASLR) 的机制,因此上图并不能代表内存中真正的布局
# Linux 内存管理
由于 Linux 使用了相同硬件技术,包括 page、MMU 和 TLB,因此前面已涵盖大部分知识。
- 例如 64 位系统依然是 48 位寻址
- (注:查了下为什么不是 64 位,据说是因为会增加系统复杂度和地址转换成本,而且现目前几乎不可能用得到,因此先仅保留使用 48 位)
当在 Linux 上分配内存时,并不会立即分配物理资源,直到访问该特定的内存区域时才会分配 —— 称为惰性分配机制,类似 Windows 保留机制类似。
注:Windows 的内存分配粒度是 64KB,而 Linux 分配内存只需按照 page 大小,即 4KB
# Linux 内存布局
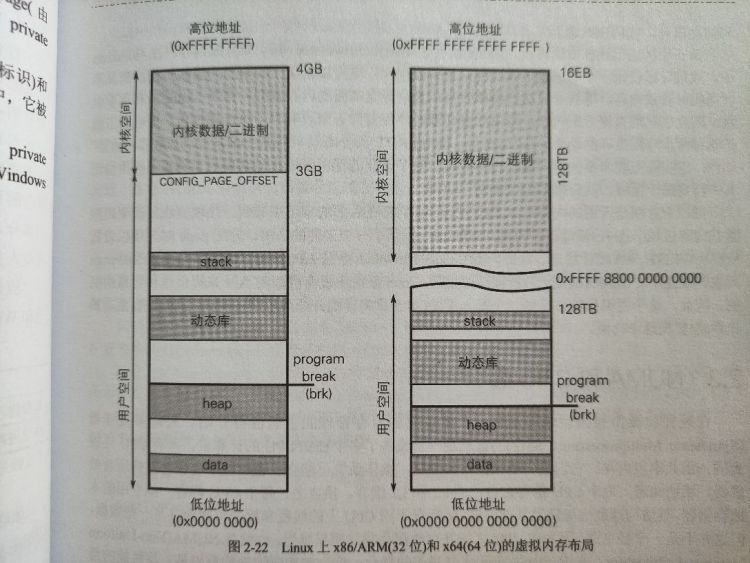
Linux 处理线程栈与 Windows 有显著差别,Linux 没有两步 (two-stage) 内存保留机制,Linux 进程的栈按照需要进行扩展,不会提前保留相应内存 page
- 由于下一个 page 按需创建,因此线程栈不会位于连续内存区域
# NUMA 和 CPU 组
对称多处理器 (symmetric multiprocessing,SMP):装备了多个独立 cpu 的计算机
NUMA(non-uniform memory architecture, 非统一内存访问):因为在 cpu 之间共享数据会存在明显延迟,因此从性能角度看,并非所有共享内存都是一样的,软件应感知到 numa 存在并选择位于本地而非更远的内存。
# 本章总结
避免随机访问,拥抱循序访问
- 注:随机访问不仅指完全随机,也指没有使用一种可预测的模式进行有序访问
提高时间和空间数据局部性
- 有时,只需要确保数据结构足够小、预先分配并重复使用就可以保证
不要放弃使用更高技巧的可能性
# 总结
说来惭愧,端午节还额外请了两天假,结果待在家里竟然... 又玩起《三国志幻想大陆》了...
这游戏几年前就玩过,这次都到三周年庆了,记得跟原神好像是同一年出的?
因此这个假期,最终也只把这本书的第二章... 结尾看完了 (之前就看了大半的)。
所以, 人类不能高估自己的自制力,最好的克制方式就是:不听、不思、不闻
