# 前言
这是去年 5 月份左右开始搞的一个 AI 工具应用,支持 Mac、Windows 平台 (但是目前只在自己的电脑测试过)。
最初是想做一个方便截图使用 (带 OCR) 的软件,不过当时一度沉迷研究 AI,特别是本地化部署的 AI 模型之类的。后边就想着直接做一个适配个人使用的工具,当时也没什么系统级的应用,感觉自己有需要的功能有时间就搞一搞加一下,直到现在,基本功能至少应该都差不多了,所以最近将项目开源了出来。
就目前来介绍,大概可以这样说:
UiharuMind 是一个开源的 AI 大模型工具,支持在本地部署自己的 AI 模型 (通过 llama.cpp),并通过 UiharuMind 的界面进行交互,支持角色配置、快捷操作 (截图、翻译)、本地知识库聊天等。同时也可以设置远程模型调用。
支持 Mac、Windows 平台。(Linux 应该也行,但是有一些平台化适配需要做,因为用不上就没弄了)。
# 功能介绍
UiharuMind 目前支持的功能有:
- 本地化部署 AI 模型:可以将本地的 AI 模型部署到本地,后端通过调用 llama.cpp 实现本地模型运行:因此支持格式也与其保持一致:GGUF,这些都可以直接在抱抱脸下载。
- 远程模型调用:也支持远程模型调用,可以通过 UiharuMind 添加对远程 AI 模型的调用。
- 常规聊天:支持工具人、角色扮演两种类型的聊天模式,也支持 DeepSeekR1 Thinking 输出。
- 快捷功能:通过一些快捷键调出快速操作,例如复制文字、图片后快速操作。
- 截图:多模态 AI OCR、截图聊天
- 知识库聊天 (支持文件、文本、文件夹、网址),需要运行本地嵌入模型。
注:
因为本地部署的 AI 模型后端是使用 llama-server 开启了一个兼容 OpenAI 格式的本地服务器,因此其实也可以作为其它应用需要的远程 AI 的后端 (本地部署)。
默认端口为 1369,连接时直接填入 IP:1369 即可。
例如:http://127.0.0.1:1369
# 剪切板文字
当复制某些文字时,会在鼠标位置处出现一本书的图标,鼠标移动上去会弹出更多可选操作:
- 解释:要求 AI 解释复制的文字的意思。
- 翻译:将复制的文字翻译为本地语言。
- 思考:要求 AI 思考复制的文字的意义。
- 询问:针对复制的文字进行额外的输入询问。
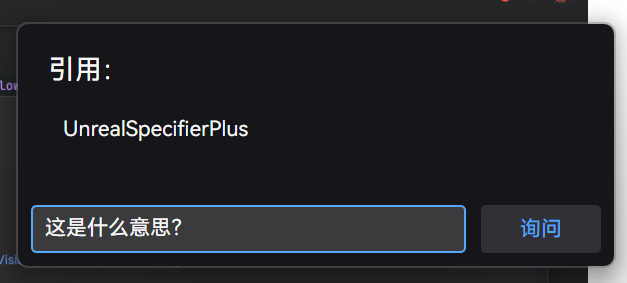
回复时会自动打开一个简单的结果窗口:
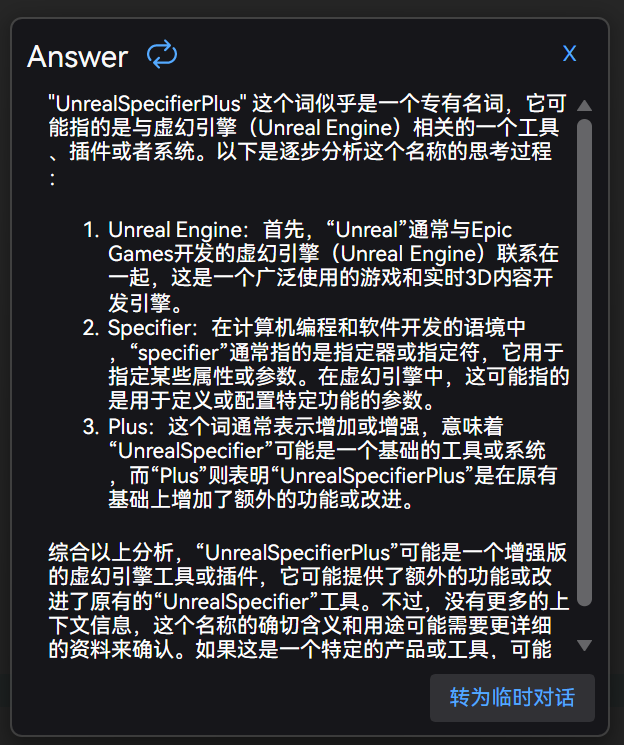
如果还想针对问题进行进一步的询问,可以点击右下角 “转为临时对话” 按钮:
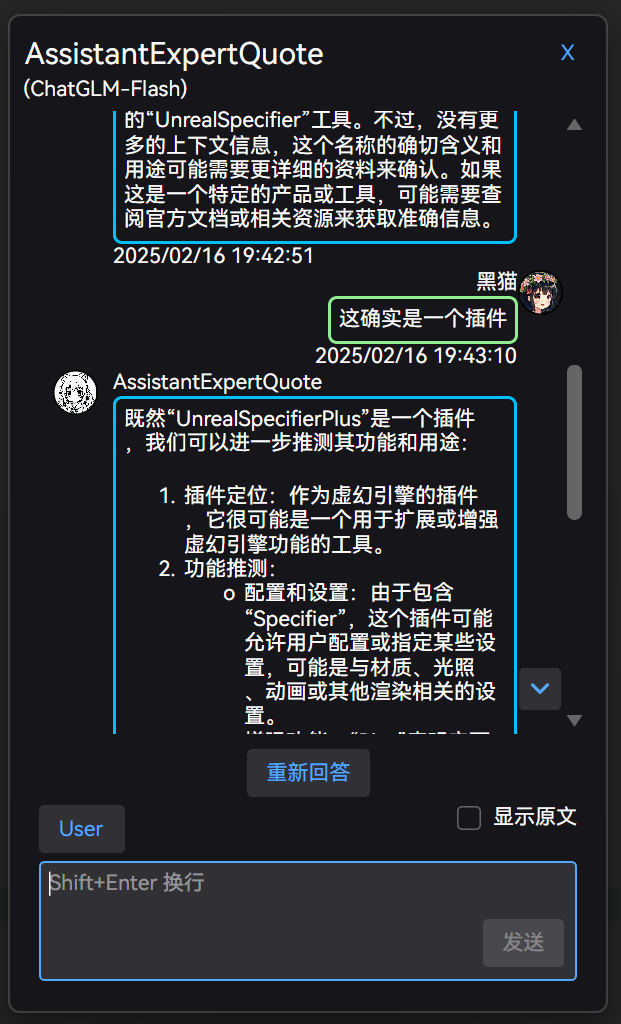
选择转为临时对话后,继续对话的内容会自动保存到聊天列表中,但是请注意:
临时对话的聊天记录只有最后一个,开启同一个功能的临时对话会覆盖之前的聊天记录。
# 快捷键
- 截图 (Alt+Shift+Z)
- 快捷询问 (Alt+Shift+A)
- 剪切板历史 (Alt+Shift+S)
- 翻译 (Alt+Shift+Q)
注:使用快捷功能时,若当前没有主动加载模型,那么会自动检测合适的远程模型调用。
主要功能可能只有截图和翻译,需要额外说一下:
# 翻译功能
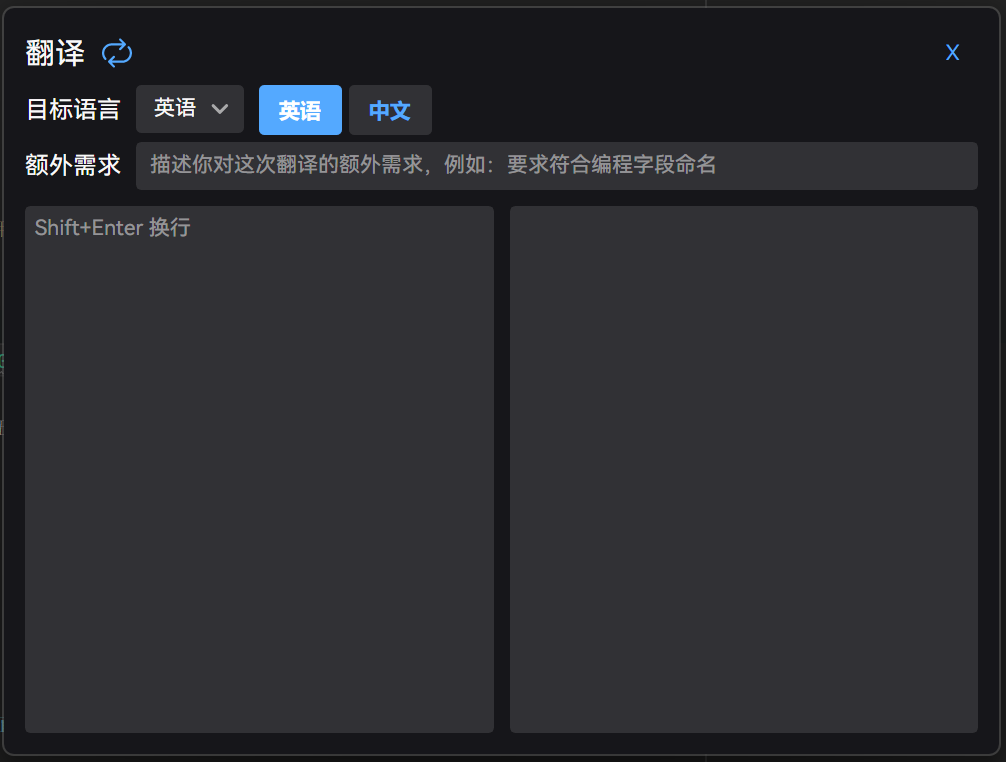
通过快捷键可以直接打开翻译界面。
# 截图功能
当截图成功后,会自动固定在显示器上:
目前的操作逻辑为:双击关闭。
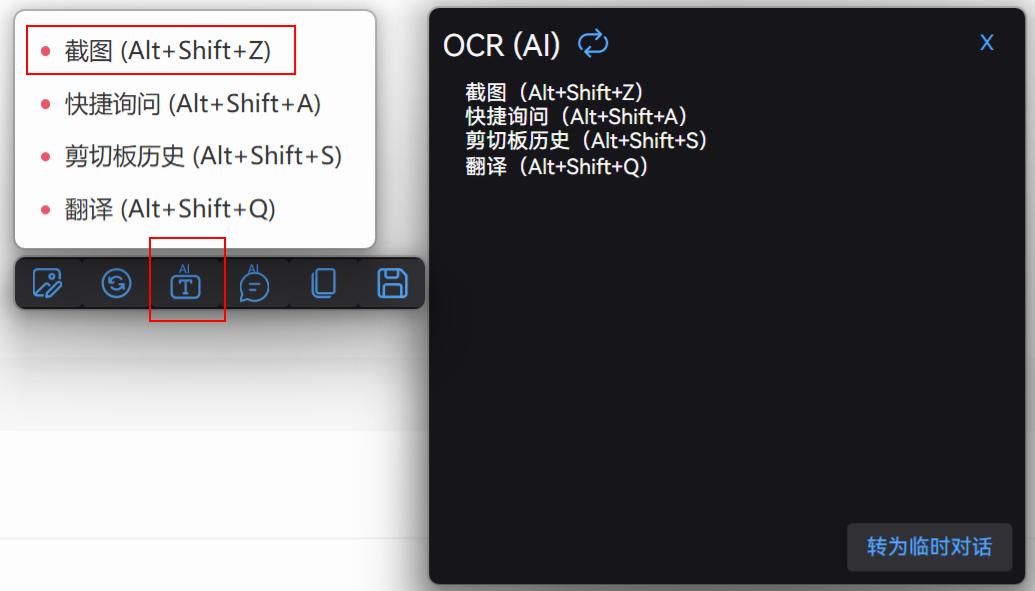
上述截图中,红框中的为 OCR 功能,可以将图片中的文字识别出来,以它为中心的按钮功能分别是:
- 左侧按钮分别为:图片编辑、图片编辑后会出现的切换回原始图片的按钮。
- 带图片对话 (可以针对图片询问问题)、复制截图到剪切板、保存截图
图片对话:

继续追问:
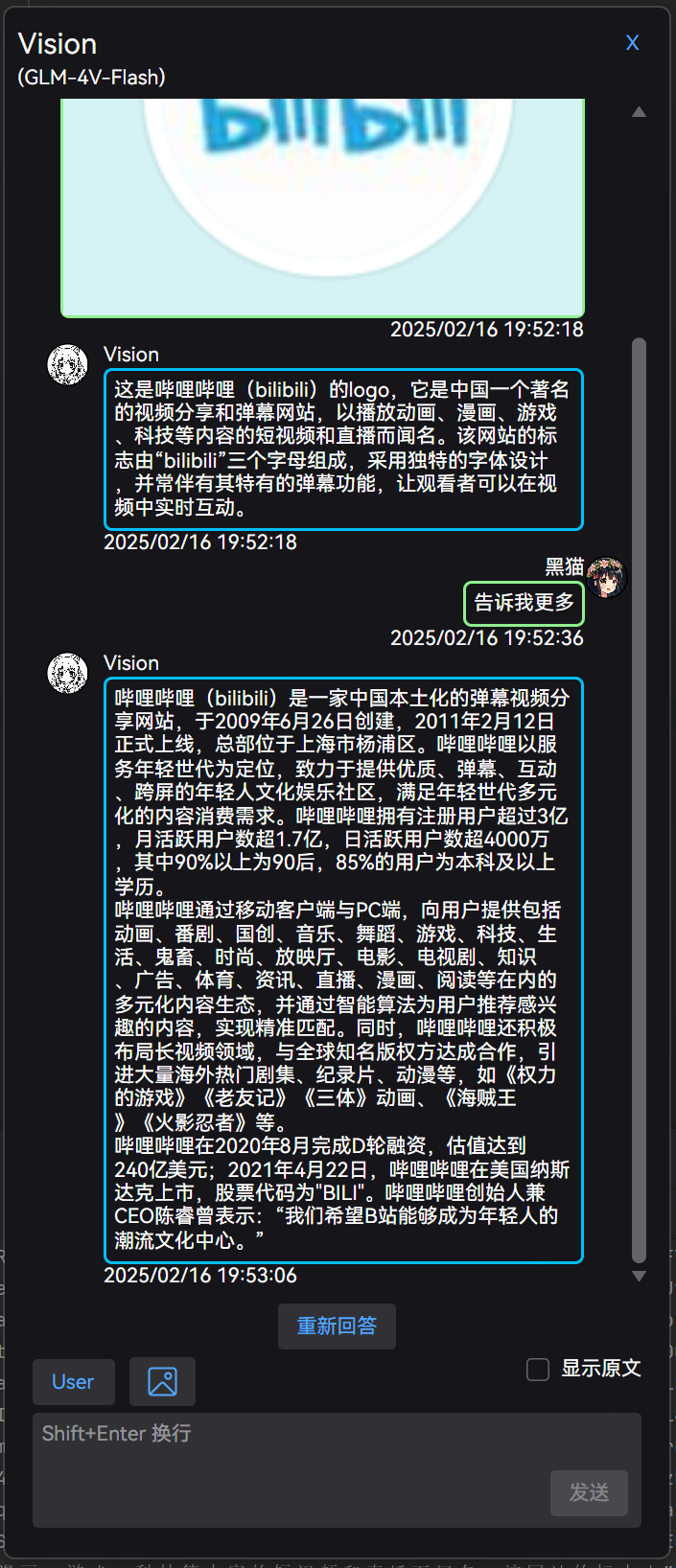
当模型支持多模态时,对话输入框顶部会额外显示 “上传图片” 按钮,可以直接上传图片进行对话。
# 本地模型部署
# 准备工作
# 1. 首先需要准备好你的 AI 模型,并将其转换为 GGUF 格式 (太麻烦一般人应该都不会搞)。,或直接下载已转换好的模型,如:抱抱脸。
# 2. 确认本地执行后端
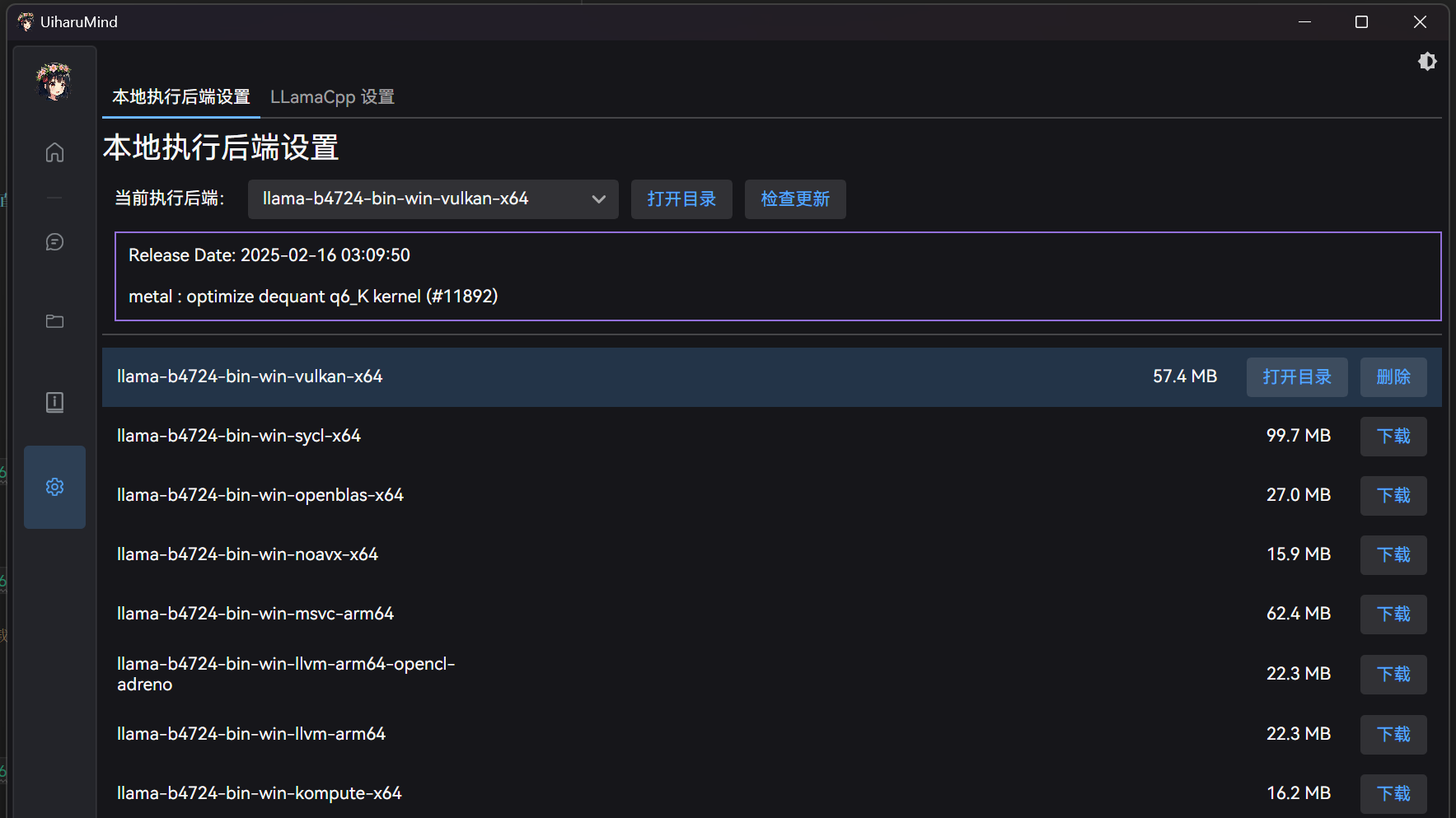
在设置界面 -> 后端 -> 选择本地后端,并确认路径正确。
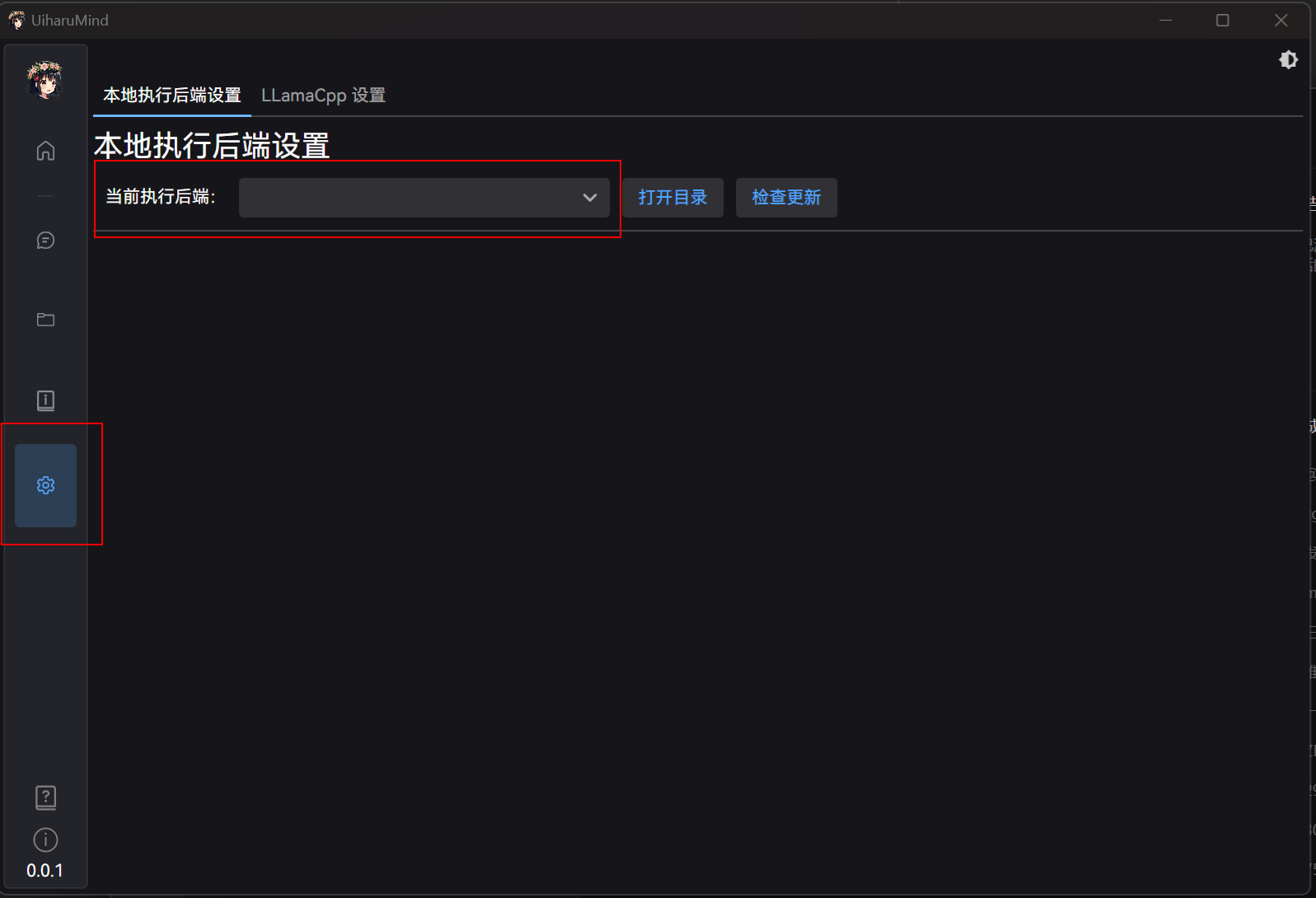
如果不存在,可以选择点击更新,会检测目前最新的运行后端:
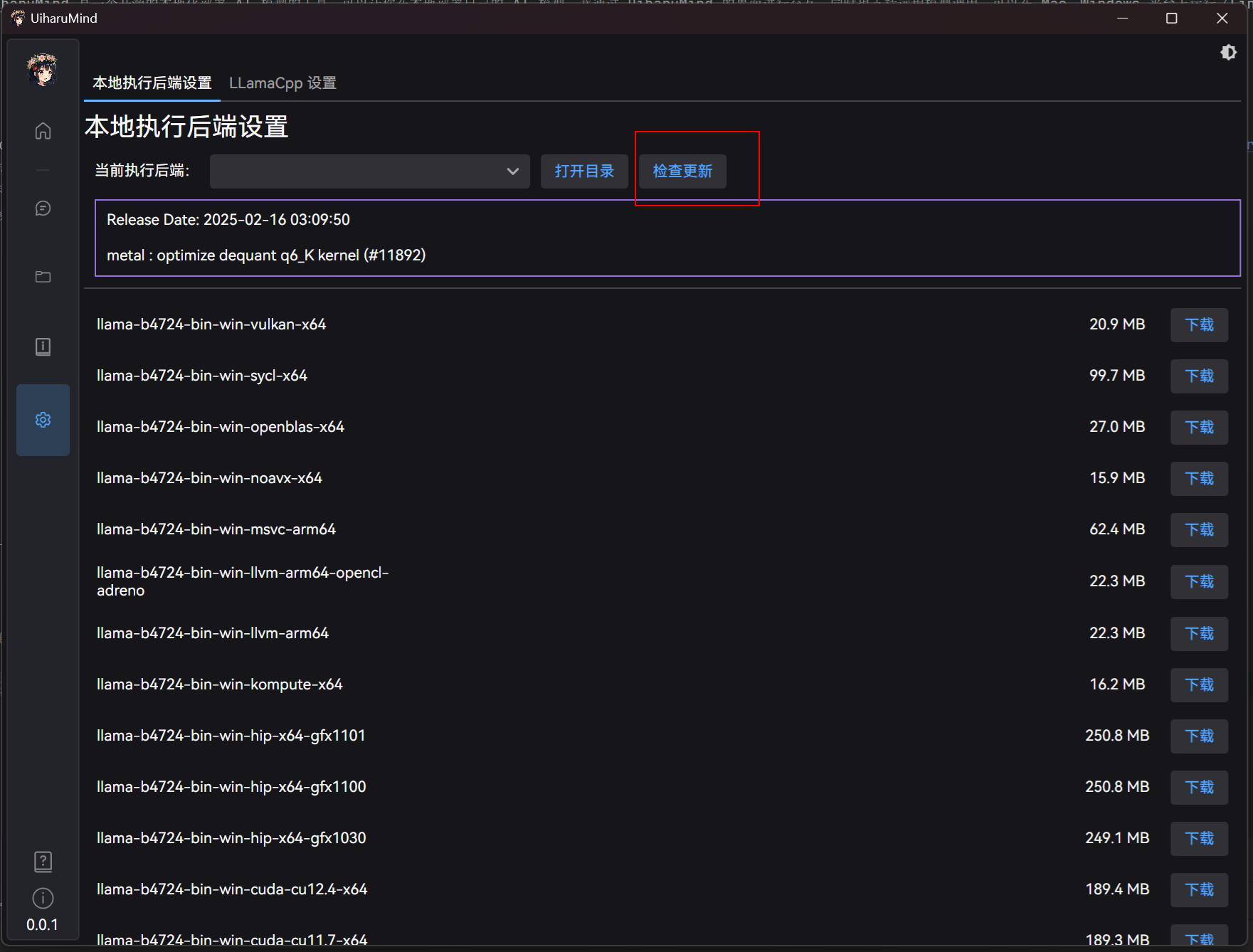
之后选择合适的后端版本,并点击下载即可。程序会自动下载并解压到指定目录:
注意:AMD 显卡专用的 ROCM 版本是带 hip 的,具体需要更具自己 GPU 型号下载,或者直接下载 Vulkan 或 OpenCL 版本。
- gfx1030(RX6800-RX6950XT)
- gfx1100(RX7900XTX 和 RX7900XT)
- gfx1101(RX7700XT 和 RX7800XT)
这里简单以 Vulkan 版本为例:

之后,进入模型界面,在模型界面左上角有本地模型目录设置,以及快捷打开模型目录的按钮:
如果想保持默认,可以直接将下载的模型放在默认目录下,否则可以点击更换按钮选择自己的模型目录。
好像现在忘了做文件即时监控刷新了,因此只有在更换模型目录后才会刷新,如果列表没有更新,可以试试更换一下目录,或者直接重启软件试一下。
如果操作正确,应该可以看到模型列表:
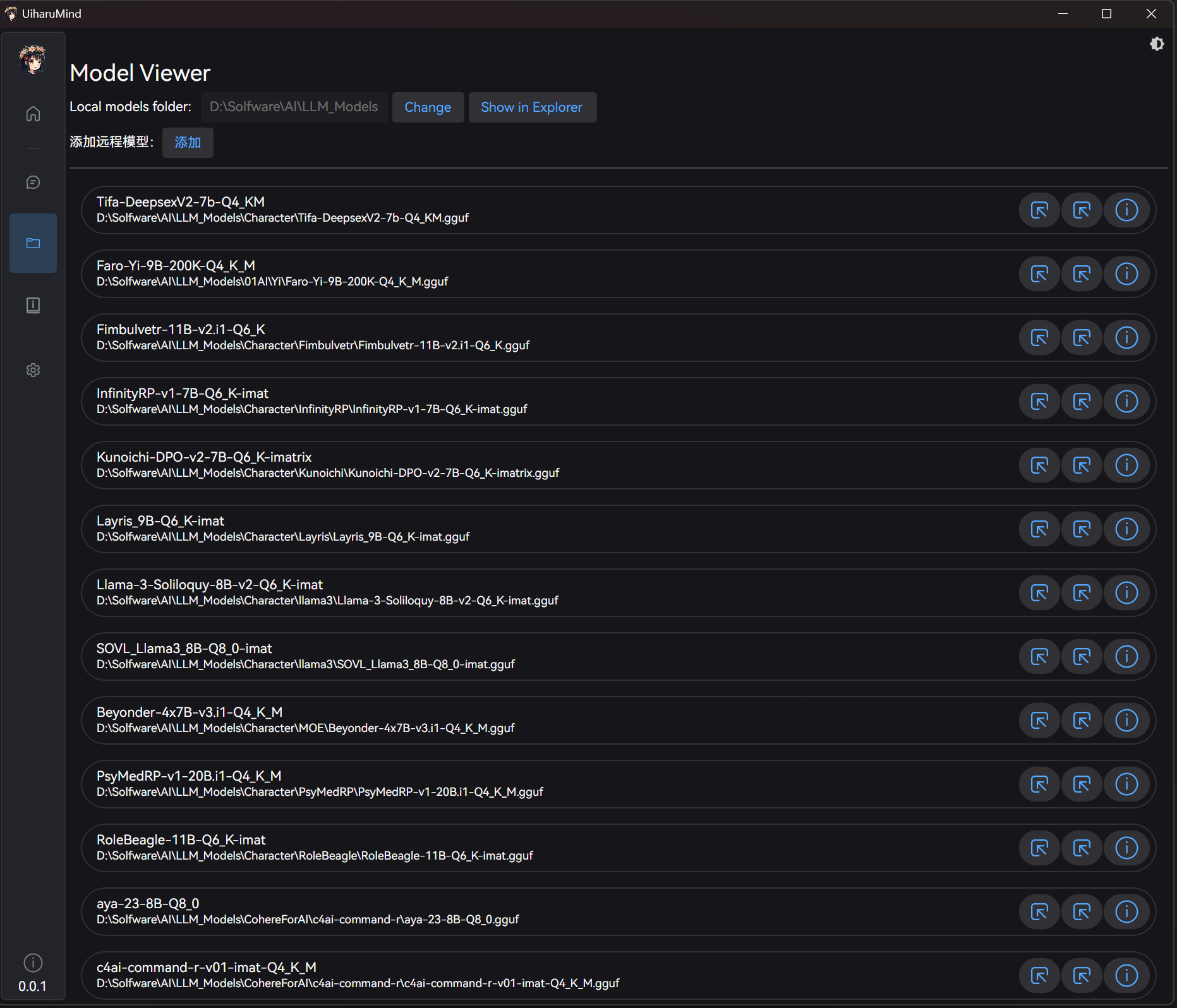
# 3. 加载模型
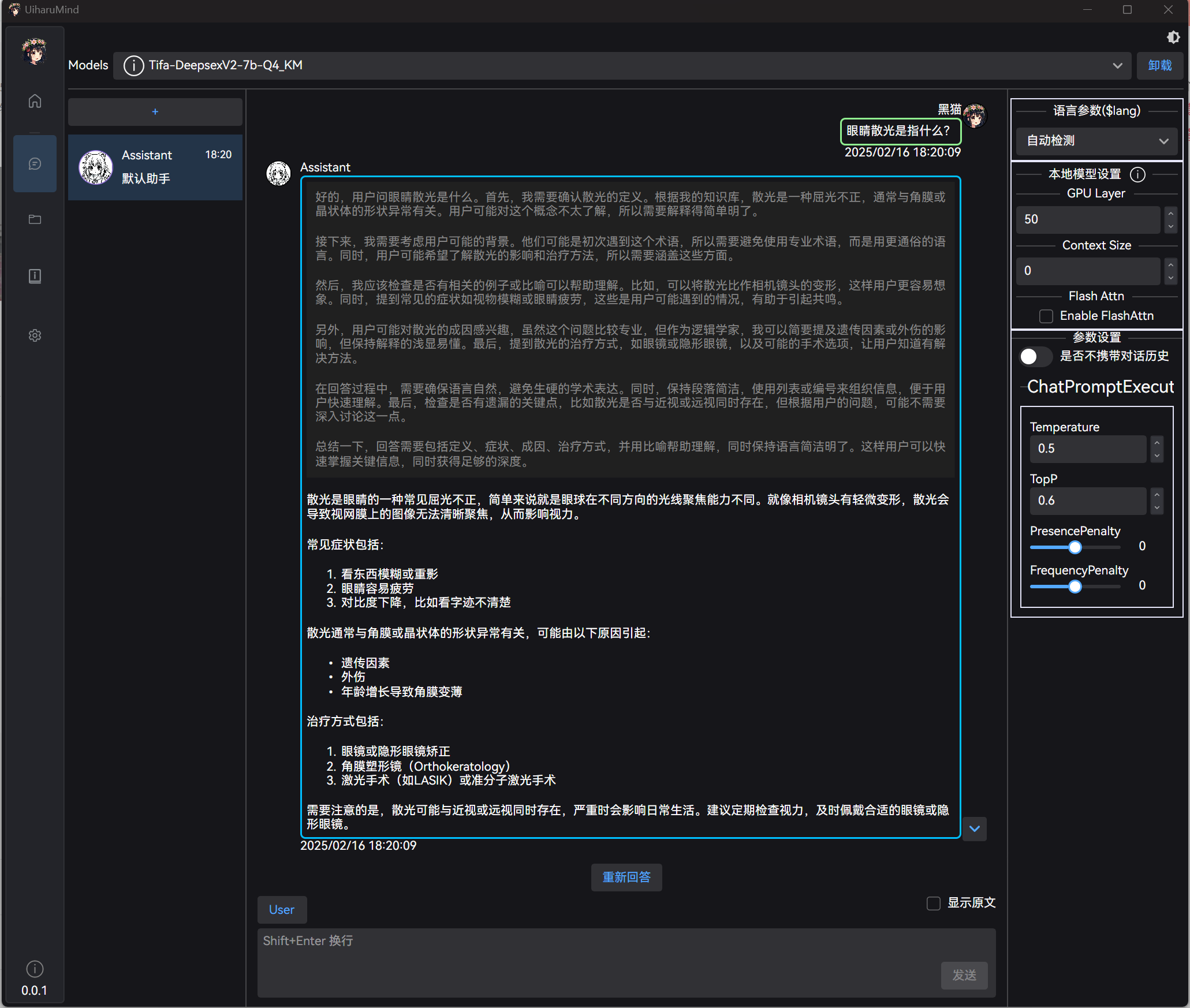
在对话页签中,界面顶部有选择加载模型的列表,点击模型名称即可加载模型:
另外,对话右侧的 “本地模型设置” 中,可以设置模型的一些参数,例如:
- GPU Layer:运行时需要卸载至 GPU 的层数,GPU 运行的层数越多,运行越快。但是请注意不要爆显存了,那同样会导致运行变得很慢。
- Context Size:加载模型时的最大上下文大小,默认为 0 时将从模型读取最大支持大小。请注意:上下文越大,要求的 RAM 越多。
如果有需要可以进行调整,例如 GPU Layer,不调整就是纯粹运行在 CPU 上了,起不到加速效果。
# 4. 对话
在对话页签中,可以进行对话,输入文字即可:
目前也简单适配了下 think 标签,后面有时间也会整个设置 (支持直接排除 think 内容之类的):
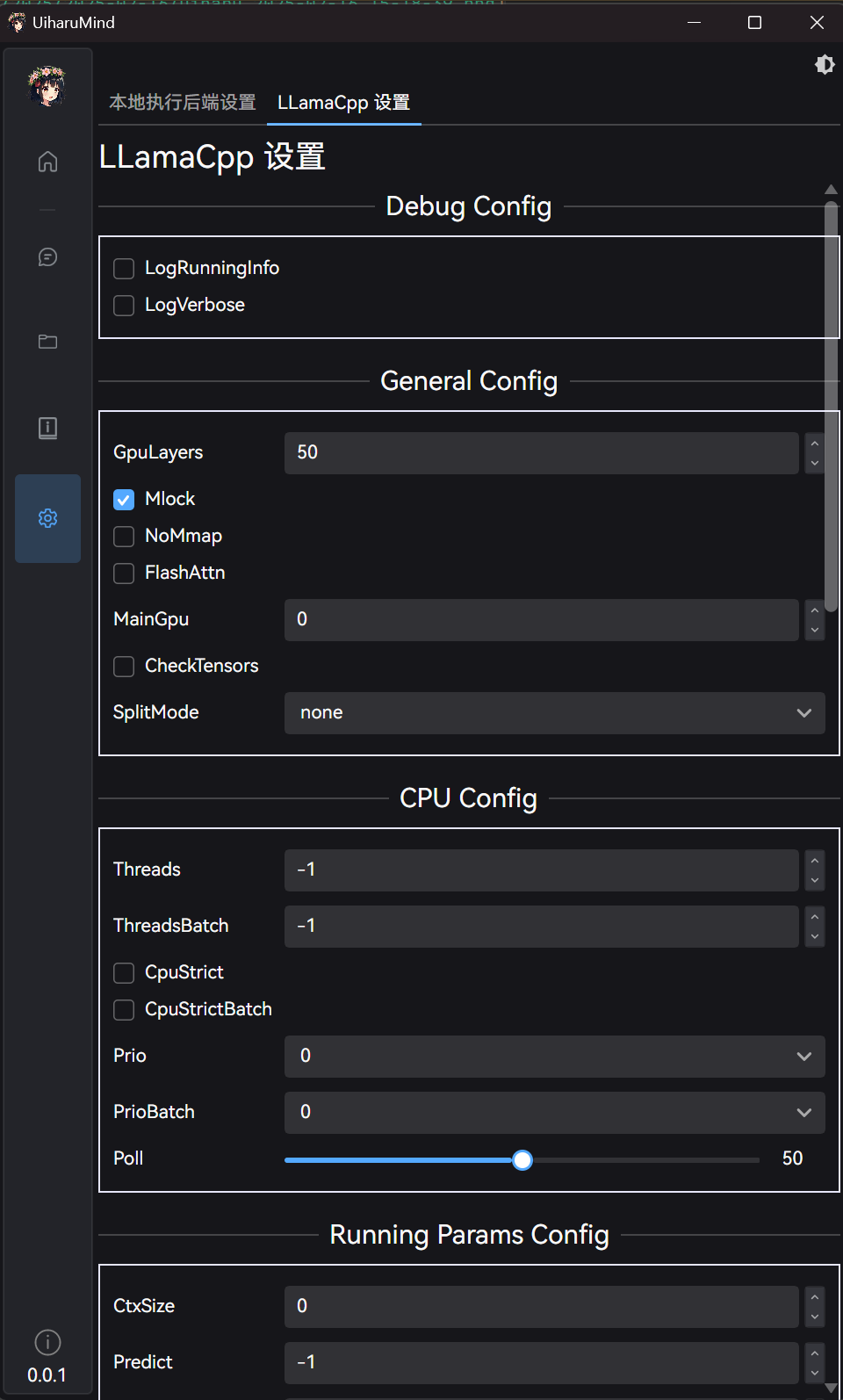
# 5. llama.cpp 全局设置
在主设置页面,还可以对 llama.cpp 一些其它参数,有需要也可以进行一定调整:
# 远程模型调用
UiharuMind 还支持远程模型调用,可以通过模型设置界面添加远程 AI 模型:
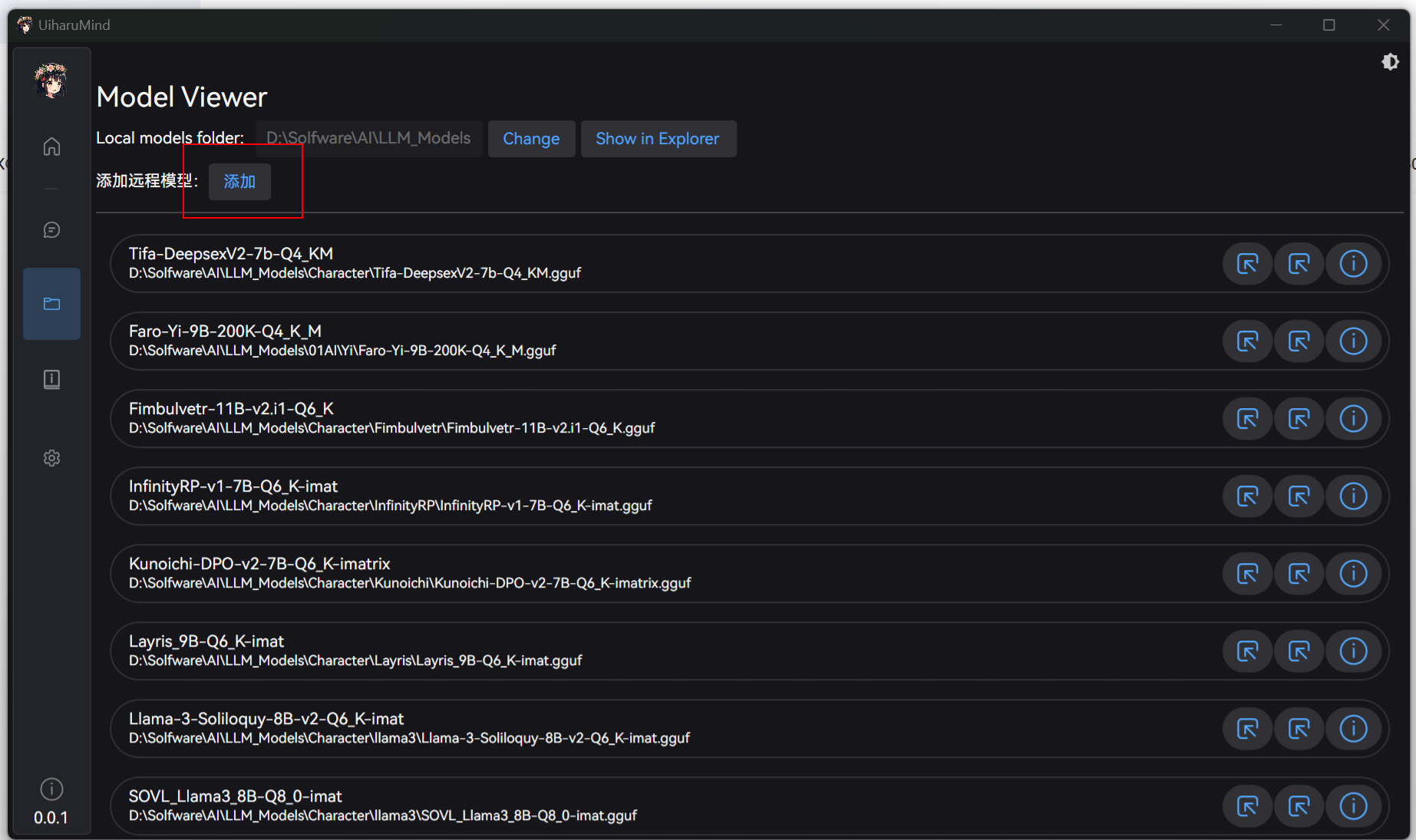
预配置的定义有智谱、混元模型,这两家都有免费 API 可以调用:
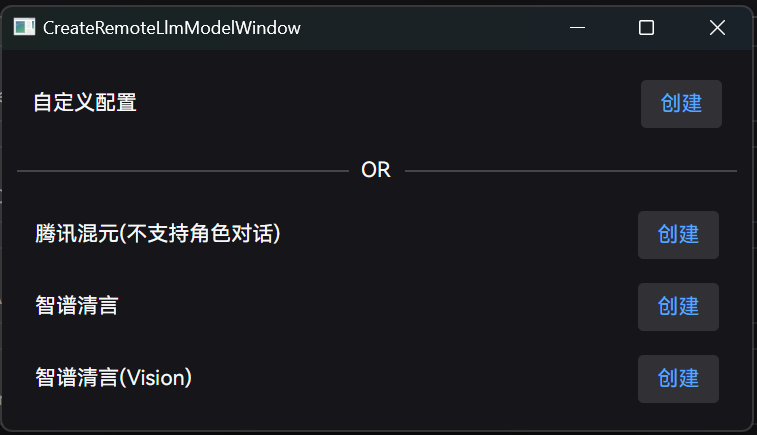
如果不在这个列表,也可以选择自定义配置,手动输入模型地址:
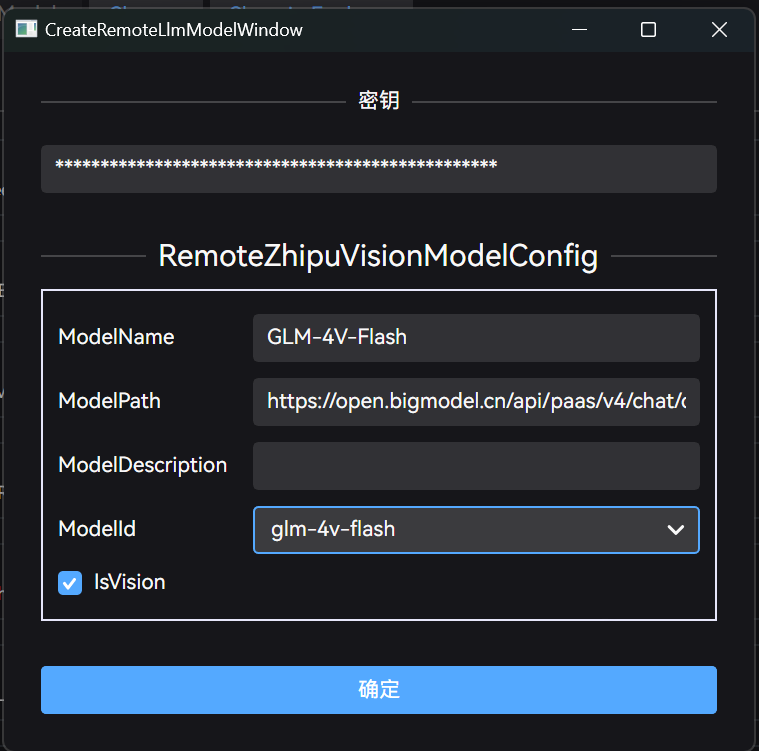
远程配置添加完毕后,列表同样会出现对应模型,同时名字上会标记为 “远程模型”:
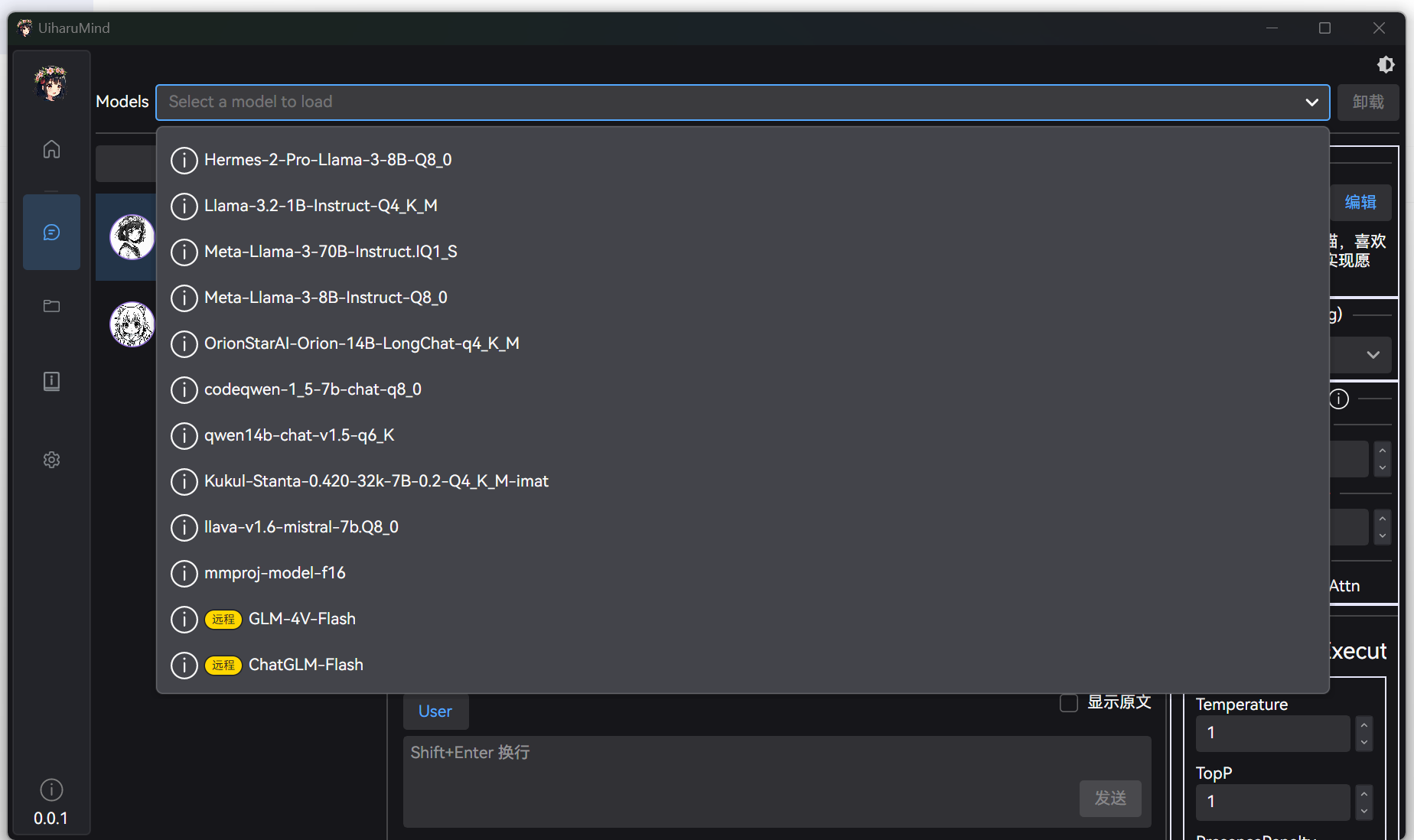
之后与本地模型一样使用,正常选择即可:
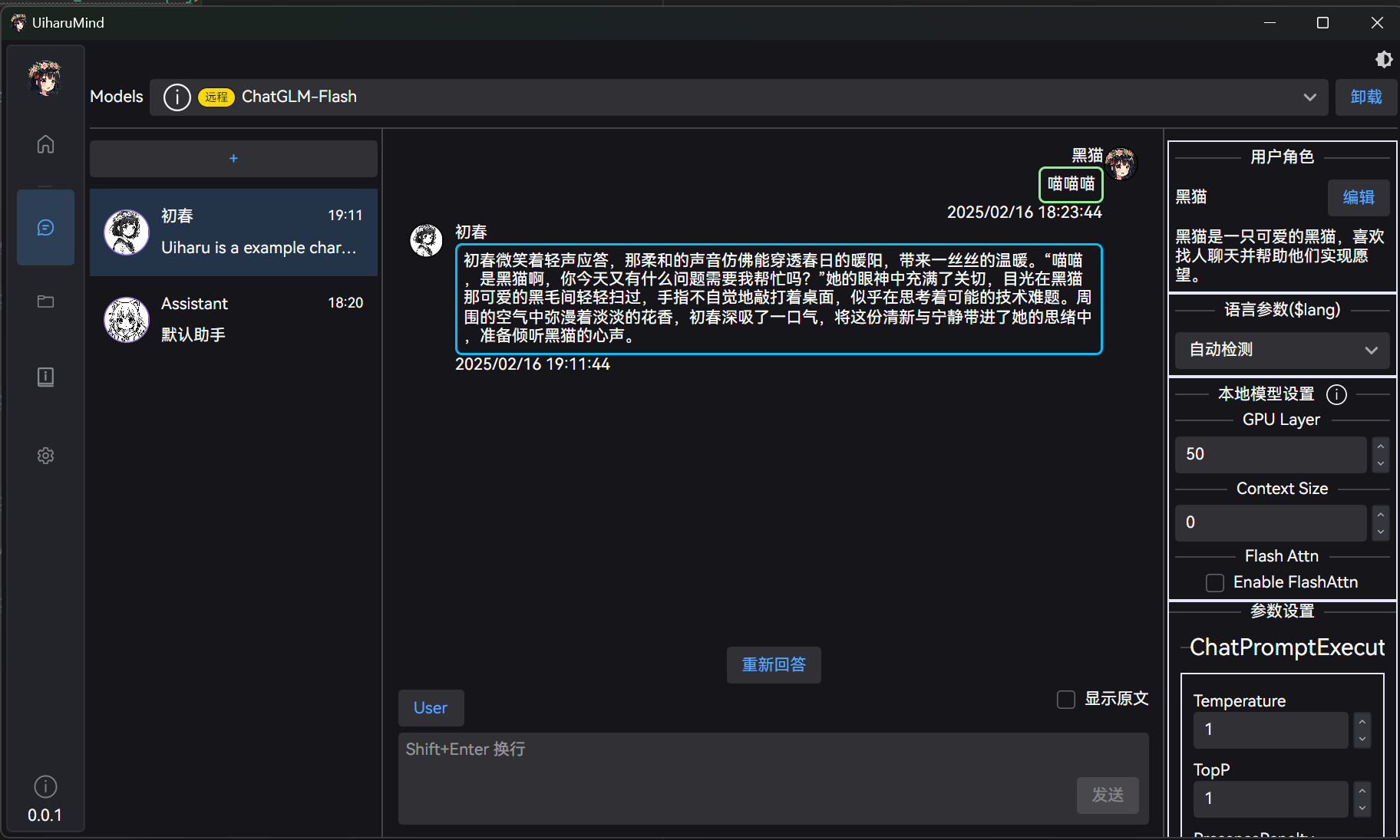
# 提示词等功能
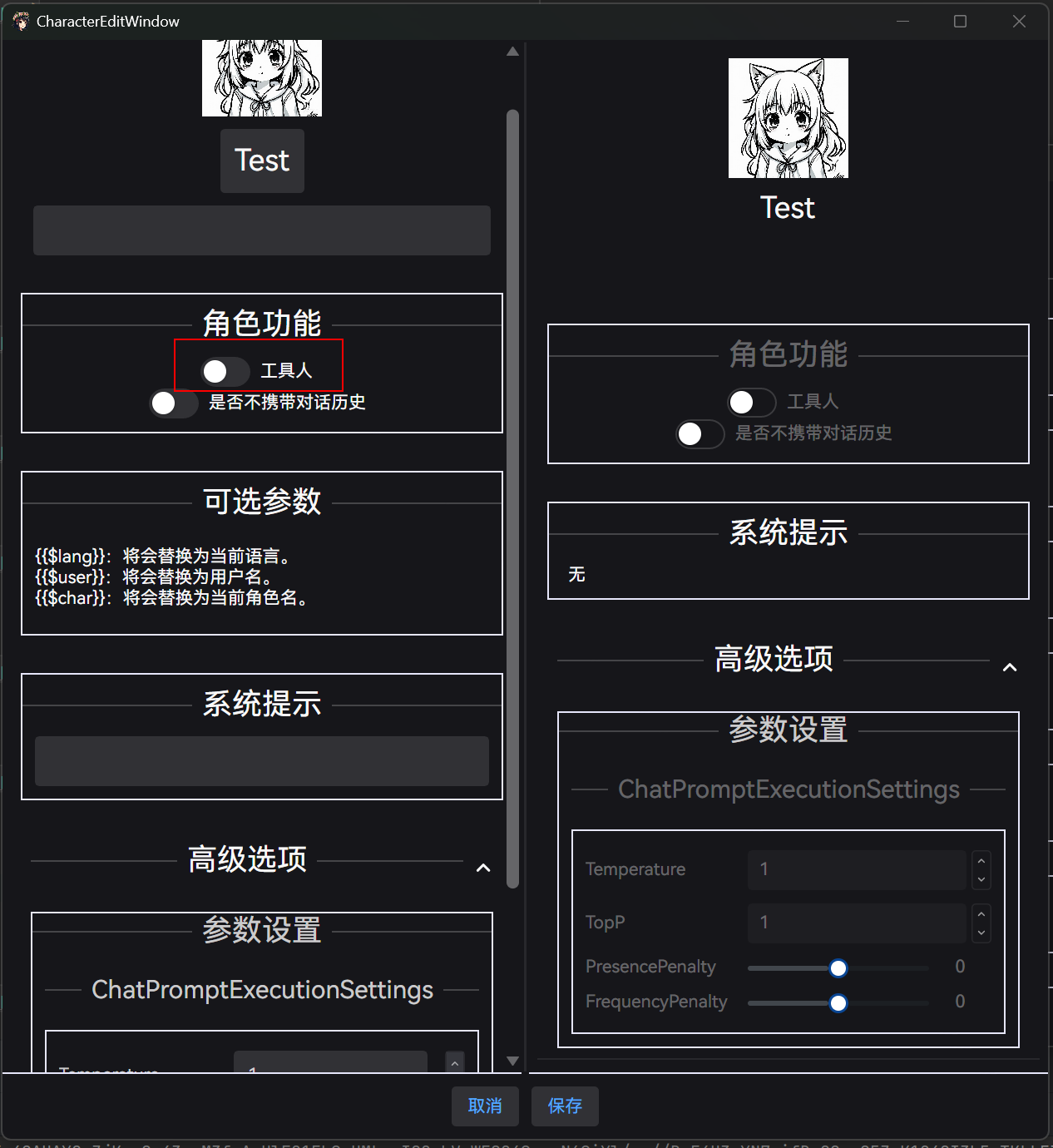
UiharuMind 还支持一些提示词功能,简单的提示这儿称为工具人,复合的提示称为角色扮演,角色扮演的角色可以挂载工具人 (复用提示)
,创建角色时可以选择性的设置:
另外,适用于角色扮演的角色,支持导入 SillyTavern 角色卡:
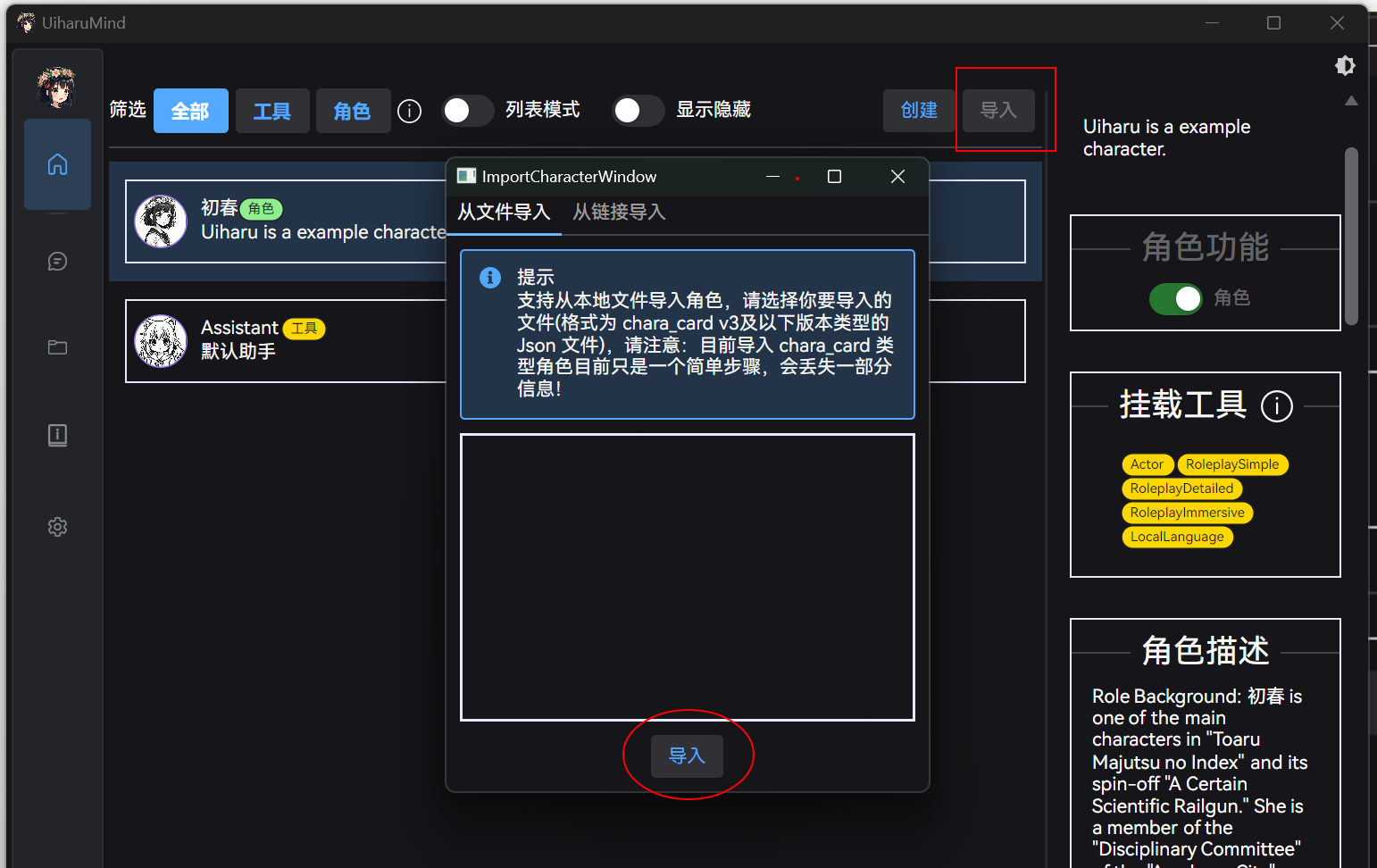
当然这个肯定没 SillyTavern 本身完善,只能说有这么个功能。
主页中会显示当前的已存在角色:
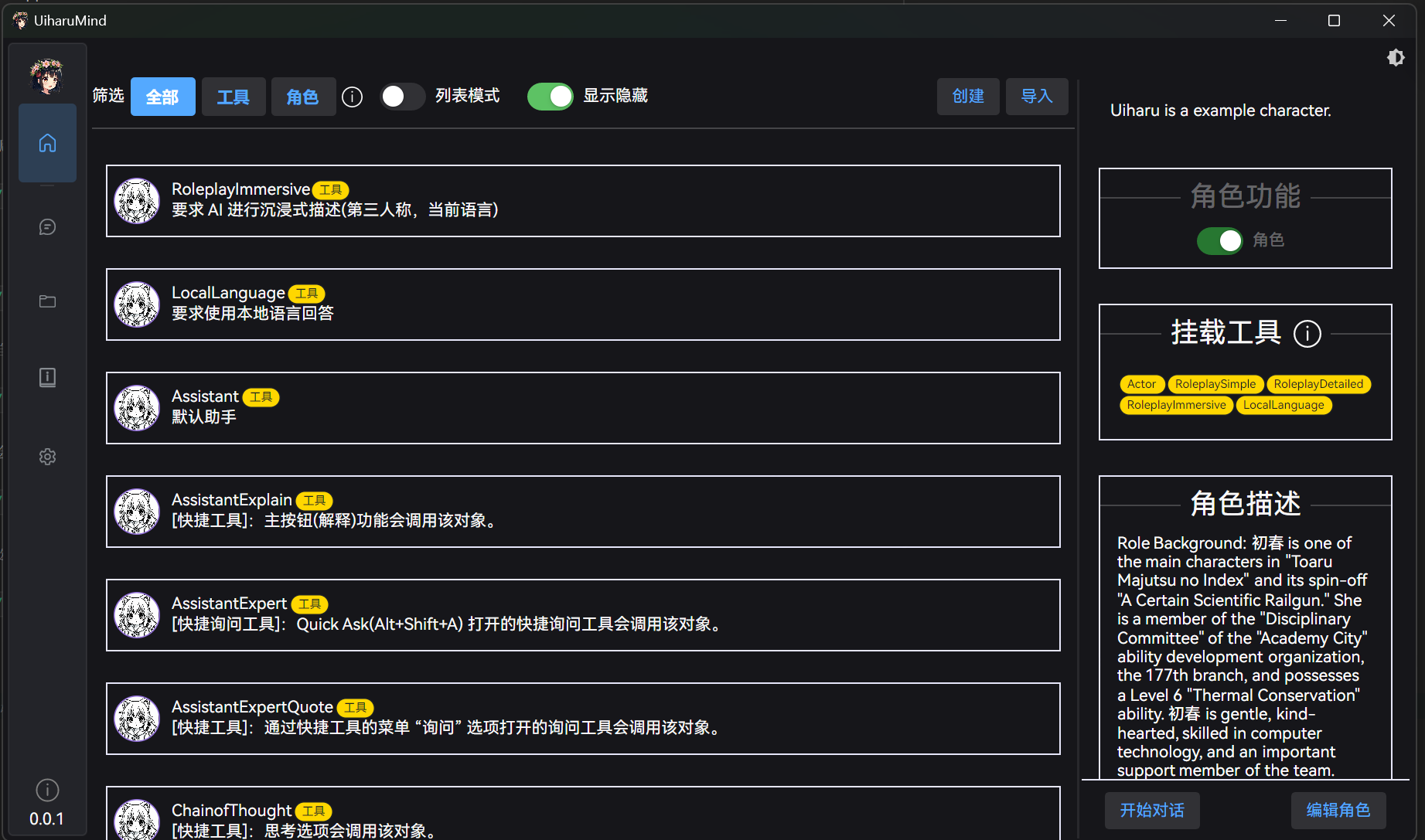
其中快捷工具使用的系统角色,勾选 “显示隐藏” 后也会显示在菜单中,描述中都有说明具体对应什么样的系统工具,可以视个人情况对其进行调整。
# 最后
还有个小提示,默认关闭主界面只是隐藏界面,如果想完全退出程序需要在系统托盘中右键退出:
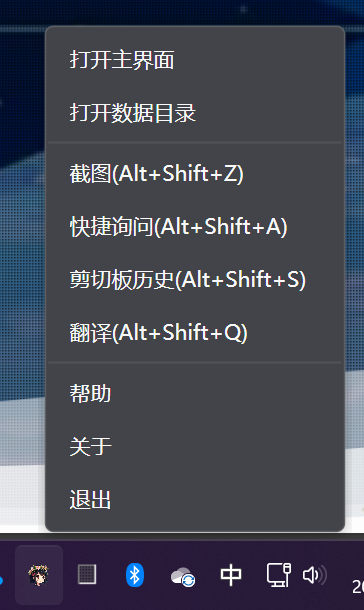
开源地址:UiharuMind
百度网盘:https://pan.baidu.com/s/1QMEj6TdjNVMrErW3s3DxPQ?pwd=au3p
